初探容器网络
演变历史
容器网络的初期阶段,容器是一种封装技术,将应用和其依赖的环境打包在一起,方便快速部署和运行。对外暴露的方式相对简单:每个容器通过对应的端口暴露,外部程序可以通过不同的端口来区分不同的容器实例和应用实例。这种方案比较直接,没有引入任何网络堆栈,因此被广大开发者采纳。但是管理起来存在一些问题,因为每个容器都至少占用宿主机的一个端口。

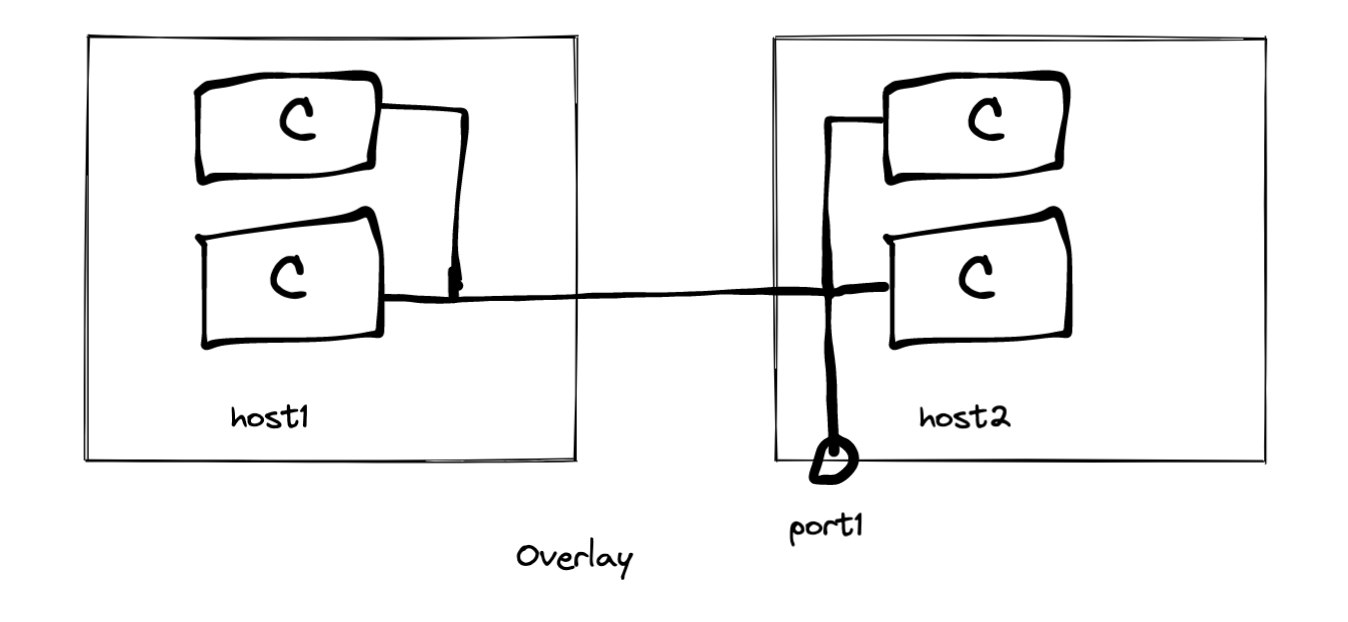
为了解决容器规模化部署管理方面的问题,引入了 Overlay 网络方案。在这种方案下,两台主机之间构建一个默认私有的虚拟网络,支持容器与容器之间的通信,每个容器在虚拟网络中都有一个独立的 IP 地址。当容器需要对外暴露时,通过虚拟网络连接主机端口,主机端口对外暴露,外部数据包可以通过主机端口进入虚拟网络,然后路由转发给特定的容器。这也就是 Overlay 网络方案的工作原理。显而易见,Overlay 的优势在于允许无限制地部署容器,并提供虚拟网络中的独立 IP 地址,但通信数据仍然需要通过真实物理网络基础设施传输。然而,企业较少使用 Overlay,因为一些传统的应用程序可能依赖于特定网络拓扑配置和直接的主机间通信方式,而 Overlay 网络方案可能需要对这些应用程序进行适配或修改,以适应虚拟网络的架构。
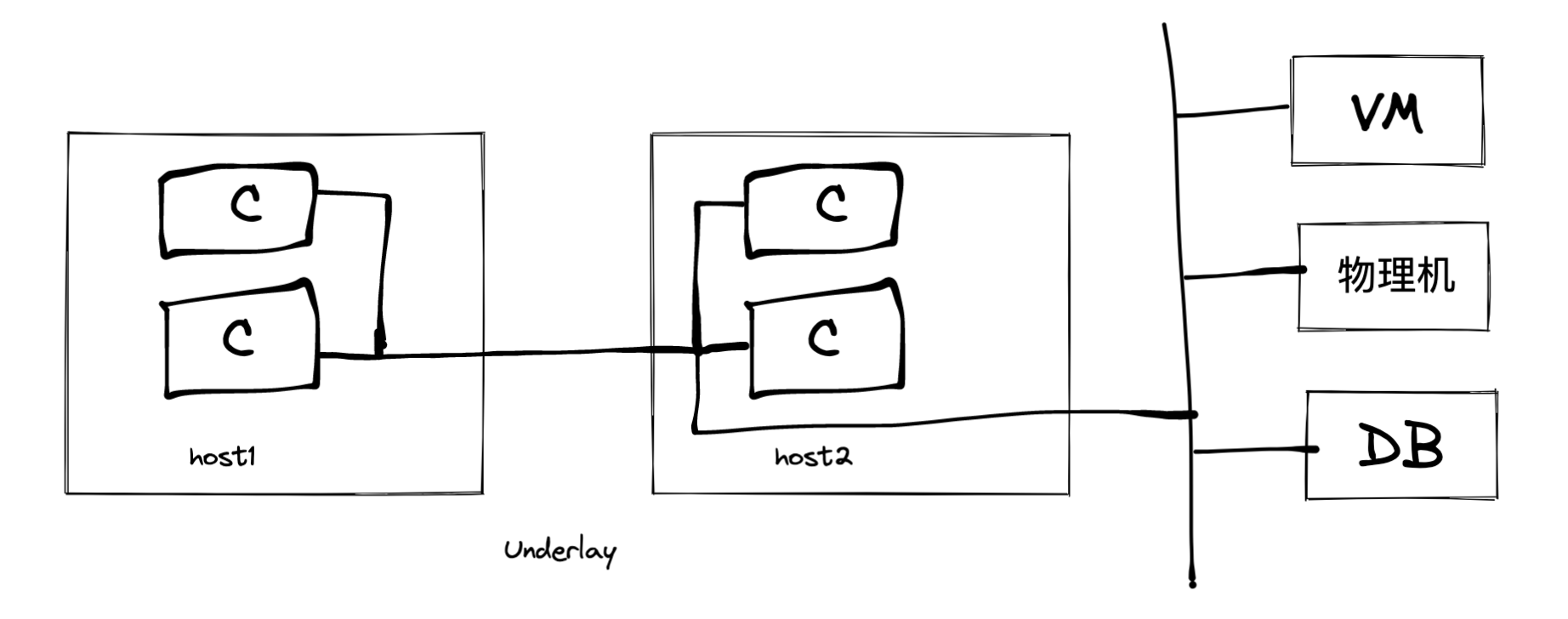
大约在 17 年左右,基于 Overlay 的 Underlay 网络方案在业界流行起来。在这种网络方案下,虚拟网络与底层网络相连,能够满足虚拟网络中容器与虚拟机、物理机以及数据库等之间互通互连的需求,成为企业级网络方案的主流。与 Overlay 网络方案相比,Underlay 本质上没有变化,只是网络连接方式上有些许不同。然而,Underlay 网络方案有着明显的缺陷,当虚拟网络与真实物理网络打通后,容器每一个 IP 地址的管理都受到物理条件制约。由于底层网络有着多种类型,比如 vlan,IPv6,SDN,VPC 等,Underlay 需要对它们都进行适配,而这种适配可能具有一定的特殊性,比如华为的 SDN 可能无法以适配物理二层的方式进行适配,可能需要调用 SDN 的一个接口去获取可路由的 IP,然后在 SDN 网络控制器中配置转发规则。
网络方案的第三个阶段是多网络框架,它支持底层多变多样的基础网络结构,同时支持应用层面的联通性和管理的便捷性。这也是适配底层网络多样性的通用性解决方案,在容器内实现 Underlay 和 Overlay 网络的互通互联,在负载均衡层实现对外端口暴露,并将数据包转发到 Overlay 和 Underlay。

Overview
容器是独立的,没有存储任何网络相关信息。沿用 Docker 官网的一句话:
A container only sees a network interface with an IP address, a gateway, a routing table, DNS services, and other networking details.
开放端口
默认不开放端口,创建或运行容器时通过指定参数来暴露端口。其实就是在宿主机创建一个防火墙规则,将容器的端口路由到容器宿主机。
1 | docker create -p 192.168.1.100:8080:80 |
如果参数重包括 localhost ip,那么只有 Docker 宿主机可以访问到:
1 | docker run -p 127.0.0.1:8080:80 nginx |
容器互通可以不用开放端口,使用 bridge network 即可。
IP address
容器会从每一个连接到的 Docker 网络中获取一个 ip,Docker 守护进程为容器执行动态子网划分和 ip 地址分配,每个网络都有一个默认的子网掩码和网关。
启动的时候只能指定连接到一个网络,但可以通过命令使得运行中的容器连接到多个网络。
1 | docker network connect |
DNS
默认继承宿主机的 DNS 配置,定义在/etc/resolv.conf中。容器连接默认网桥的时候会拷一份这个文件。连接自定义网络的时候会使用 Docker 内置的 DNS 服务器,它将外部 DNS 查询转发给宿主机上配置的 DNS 服务器。
同理,在开启和创建的时候能通过参数配置 DNS 解析。
有时候需要在容器中访问宿主机,那么需要将宿主机的地址通过域名映射的方式传给容器。而在宿主机上/etc/hosts中的文件不会被容器继承,可以在启动时这样达到同样的效果。
1 | docker run --add-host=docker:93.184.216.34 --rm -it alpine |
Network drivers
Docker 的网络子系统是可插拔的,使用默认的驱动程序来提供核心的网络功能。
bridge
默认的网络驱动,如果没有特殊指定一个驱动,就会创建这种网络类型,它常用于应用程序跑在容器中,需要与其他在同一宿主机上的容器进行交流。
在网络方面,网桥是在网段(network segments)之间转发流量的链路层设备,可以是硬件设备,也可以是运行在主机内核的软件设备。就 Docker 而言,网桥使用软件网桥,允许连接到同一个网桥的容器进行通信,同时提供与未连接到该网桥的容器的隔离。Docker 桥接驱动程序会自动在宿主机中安装规则,使得不同网桥上的容器之间不能直接通信。
当然,它只适用于运行在同一个 Docker 守护进程宿主机上的容器,对于不同 Docker 守护进程宿主机上的容器之间的通信,可以在 OS 级别管理路由,或者用覆盖网络(overlay network)。
启动 Docker 时会自动创建一个默认的网桥,名字也叫 bridge,新启动的容器除非特殊指定,否则也会连接到它。也可以创建自定义的网桥,
自定义网桥与默认网桥
-
自定义网桥提供容器间的自动 DNS 解析。默认网桥的容器只能通过 ip 互相访问,而自定义的可以通过别名来互相解析,灵活度更高且更易迁移。
-
自定义网桥能做到更好的隔离。所有没指定–network 的容器都会连到默认网桥,不相干的容器间也能进行访问,可能造成不好的影响。
-
容器能随时与自定义网桥连接或分离。在容器的生命周期内可以随时连接或断开与自定义网桥的连接,但是要从默认网桥中移除容器,得停止容器并用不同的网络选项重新创建容器。
-
自定义网桥可单独进行配置 比如 MTU 和 iptables 规则,默认网桥的所欲容器都用相同的设置,配置网桥后得重启 Docker。
-
默认网桥上的容器共享环境变量
通过如下命令来创建或移除自定义网桥、亦或是将容器连接或断开与某个网桥的连接时,实际上发生的是 Docker 守护进程使用操作系统特定的工具去管理底层网络基础设施(如在 Linux 上添加或移除网桥设备或配置 iptables 规则)。
1 | docker network create my-network |
默认网桥是 Docker 的历史遗留,不推荐在生产环境使用,而且配置它还需要额外的步骤,且存在技术缺陷(如上与自定义网络的差异)。
配置默认网桥
更改/etc/docker/daemon.json,更改后需要重启 docker 才会生效。
1 | { |
看官网说的:Docker network failures with more than 1002 containers · Issue #44973 · moby/moby · GitHub 由于 Linux 内核限制,当一个网桥连了一千多个容器时,会变得不稳定,容器的通讯可能会断开。
Overlay
Overlay 在多个 Docker 守护进程主机之间创建一个分布式的虚拟网络,使得连到该网络的容器能经过加密后相互通讯,Docker 透明处理每个数据包到目标主机以及目标容器的路由。
前文提到过,在 Overlay 网络方案下,容器网络自建虚拟子网且自置一个 IPAM,可以有无限的虚拟 ip 地址分配,每一个在虚拟子网内的容器都具备一个独立可访问的 ip,通过对外暴露端口(即 Kubernetes 的 nodeport),可以访问到任意一个容器。但是虚拟机需要与容器通讯时,当虚拟机需要访问容器时,需要一层 NAT 网络转换,且无法指定某个容器实例,相当于随机网络访问。
Host
移除容器与宿主机的网络隔离,直接使用宿主机的网络。使用这种模式,容器会共享宿主机的网络命名空间(network namespace),这意味着 Docker 守护进程不会为该容器分配 ip,而该容器也不需要手动去暴露端口,在容器中跑了 80 端口的应用,宿主机就能直接通过自己的 80 端口访问到。
主机网络模式(host)主要用来优化性能,能减少大量端口映射导致的网络地址转换(NAT)损耗,而且不需要为每个端口创建代理。
Linux 内核网络
iptables 在 SLB、Container、Istio 以及 Kubernetes 等服务中应用非常广泛,比如容器和宿主机端口映射、Istio 中的透明流量劫持、Kubernetes 核心组件 kube-proxy 的 IPVS 模式等等都是通过 iptables 实现的。此处简要介绍 iptables 以及 Netfilter。
Netfilter
iptables 的底层实现是 Netfilter,它提供一整套 hook 函数管理机制,使得数据包过滤、包处理(设置标志位、修改 TTL)、地址伪装、网络地址转化、访问控制、协议连接追踪等成为可能。五个主要的 hook 链包括:PRE_ROUTING、LOCAL_IN、IP_FORWARD、LOCAL_OUT、POST_ROUTING。主要原理如下:
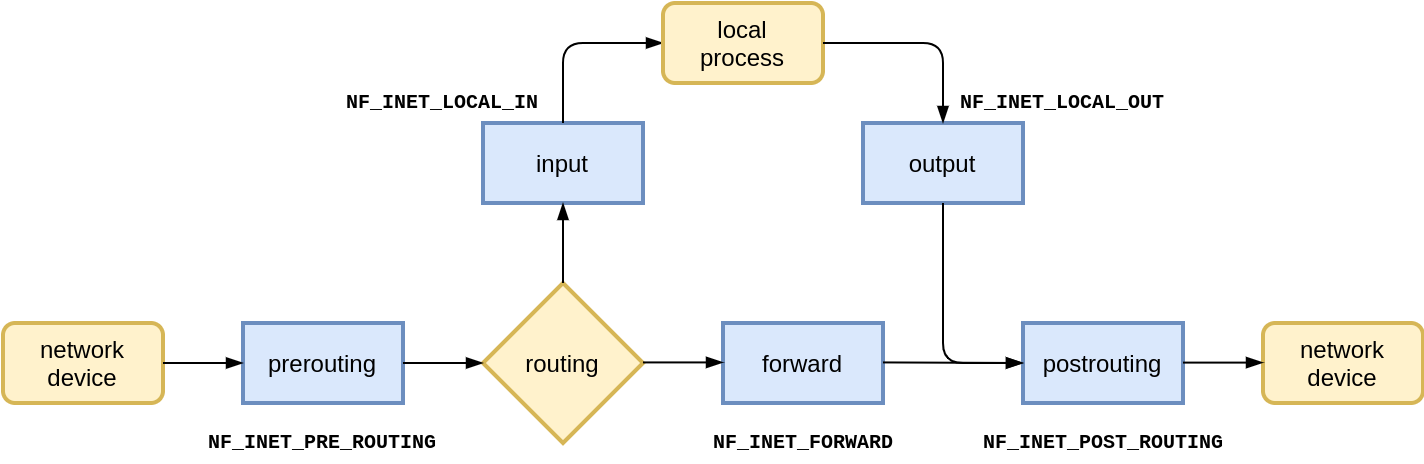
当网卡接收到一个包送达协议栈时,会在这几个关键 hook 处判断是否有对应的钩子函数,然后进行处理。
在 Linux 接收网络数据包的过程中,IP 层接受数据包的入口处理便是经过了 NF_HOOK 的过滤,如果有复杂的 filter 规则,会在此处加大网络延迟。
1 | // file: net/ipv4/ip_input.c |
iptables
iptables 是 netfilter 的操作接口,在用户空间管理应用于数据包的自定义规则,netfilter 则根据规则对应的策略处理数据包。实际上,iptables 的规则就是挂在 netfilter 钩子上的函数,用来修改数据包内容或过滤数据包,iptables 的表就是所有规则的逻辑集合。
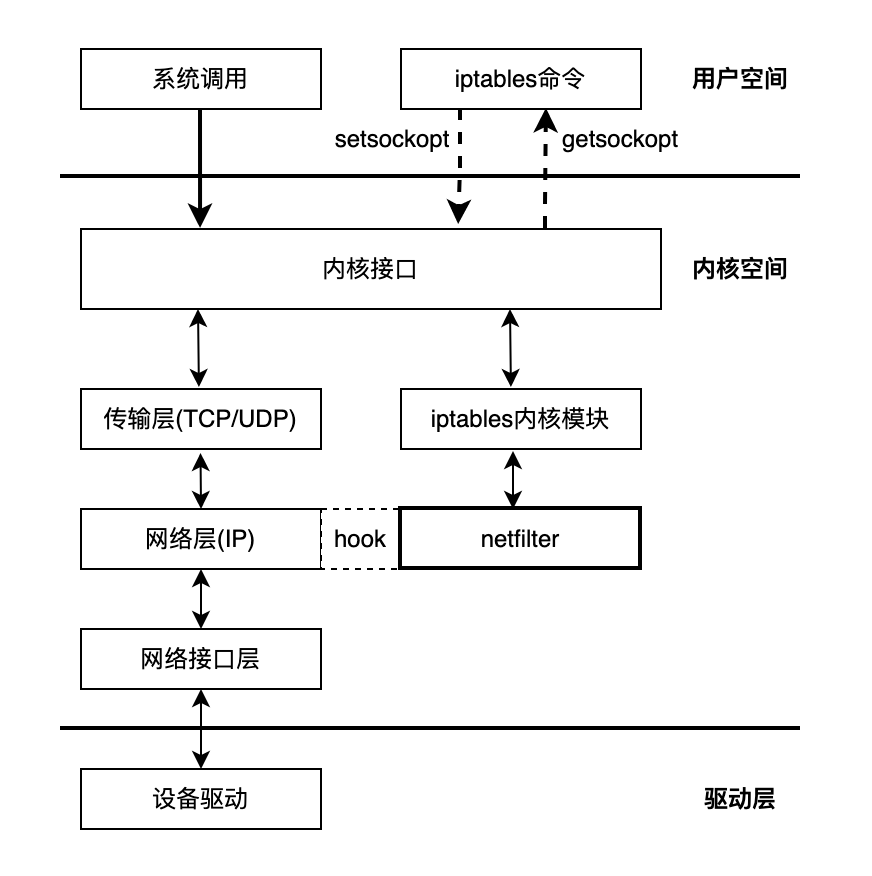
对 Linux 稍有了解的都知道:iptables 就像繁忙城市交通中的交警,负责管理和控制网络数据包的流动。iptables 分为用户空间和内核空间两部分。用户空间的 iptables 命令向用户提供访问内核 iptables 模块的管理界面,而内核空间的 iptables 模块在内存中维护规则表,实现表的创建以及注册。
在 iptables 中,有四表五链的概念,每个表包含多个数据链,防火墙规则需要写入到具体的数据链中。
四表包括:
-
raw 表:负责控制 nat 表中连接追踪机制的启用状况。
-
managle 表:负责数据包的拆解、修改和再封装。
-
nat 表:负责数据包的网络地址转换。包括 SNAT 和 DNAT,SNAT 解决内网地址访问外部网络的问题,通过在 POSTROUTING 修改源 IP 实现,DNAT 解决内网服务要能被外部访问到的问题,通过 PREPROUTING 修改目标 IP 实现。
-
filter 表:负责数据包过滤功能,包括 drop、reject 等。
一个 IP 包经过 iptables 的处理流程如下,能直观看到各个表影响着不同的链:
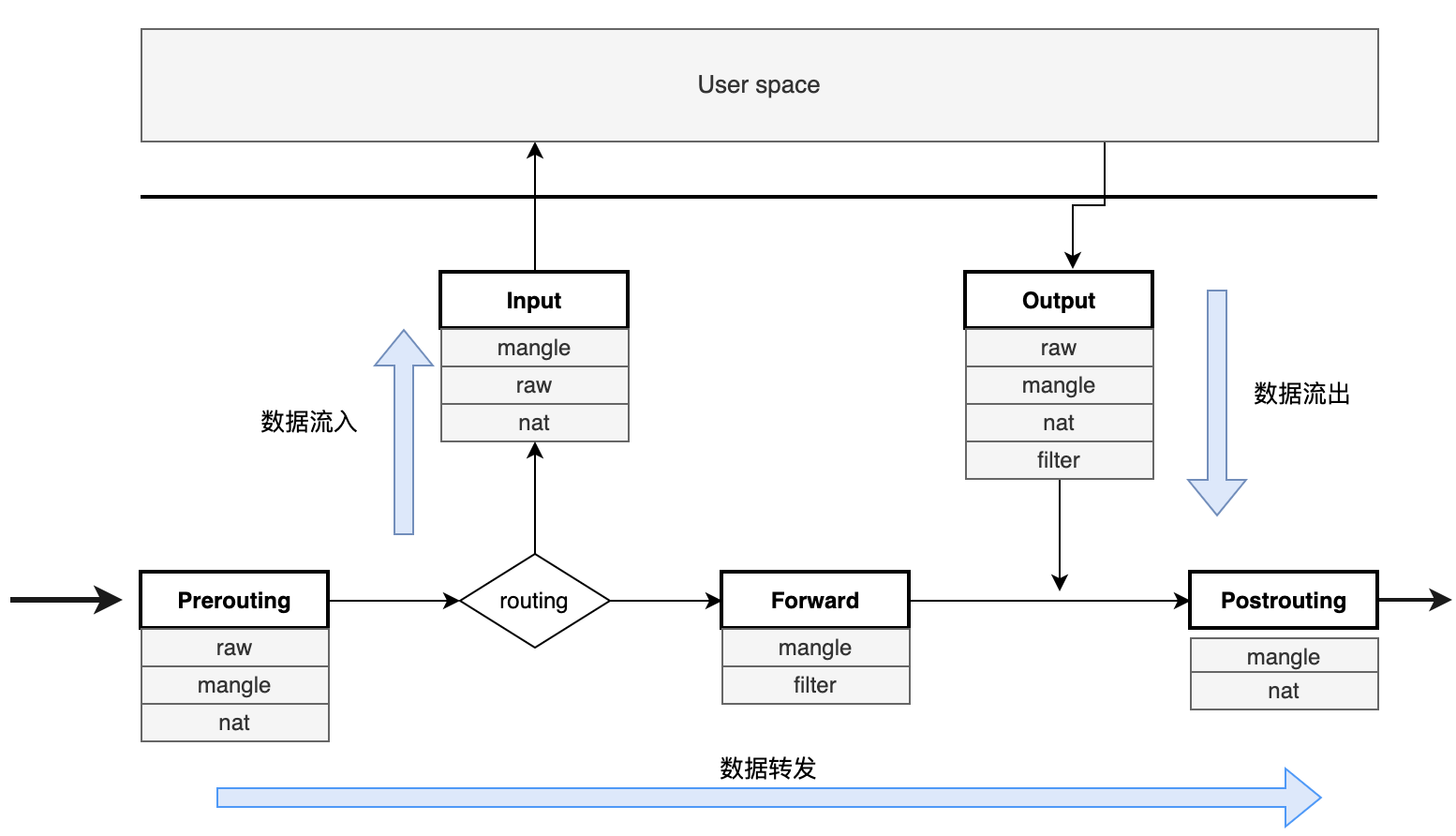
通常情况下,一条 iptables 规则包含匹配条件和动作两部分,匹配条件如协议类型、四元组元素等,匹配条件可以组合,动作主要包括:
-
DROP:直接丢弃数据包
-
REJECT:返回 connection refused 或 destination unreachable 报文
-
QUEUE:将数据包放入用户空间队列,供用户空间程序使用
-
RETURN:跳出当前链,不再匹配后续规则
-
ACCEPT:允许数据包通过
-
JUMP:跳转到其他自定义链继续执行
以下是 iptables 防火墙的规则链,Chain INPUT 表示处理进入计算机到数据包,Chain FORWARD 用于处理通过计算机转发到数据包,Chain OUTPUT 处理离开计算机的数据包,Chain DOCKER 用于处理与 Docker 容器相关的数据包,其中 ACCEPT 表示允许任何源的目标端口为 ssh 的 TCP 包通过目标为 172.17.0.3 的主机(容器),即允许 SSH 连接到 Docker 容器。
1 | [root@harbor ~]# iptables --list |
网络虚拟化
主要技术是 Network namespace,以及各类虚拟设备如 Veth、Linux Bridge 等,它们彼此协作,将独立的 namespace 连接形成一个虚拟网络。
Network namespace
namespace用于 Linux 内核隔离内核资源,其中 network namespace 则用于隔离网络资源。它能创建多个隔离的网络空间,通过man ip-netns可以知道:该网络空间内的防火墙、网卡、路由表、邻居表、协议栈与外部都是独立的(逻辑上),不管是虚拟机还是容器,当运行在独立的命名空间时,就像是一台单独的主机一样。
“network namespace is logically another copy of the network stack, with its own routes, firewall rules, and network devices.”
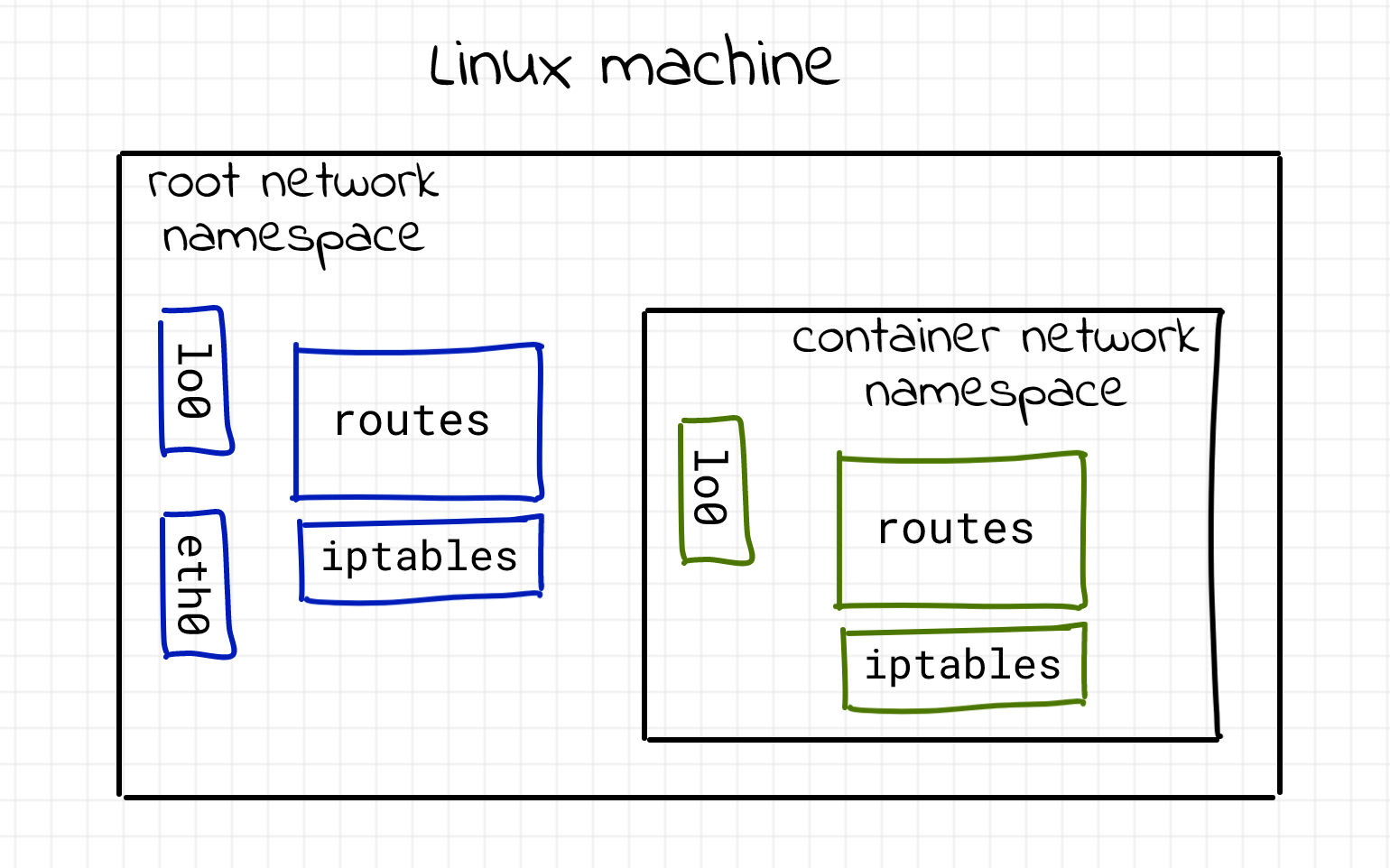
创建网络命名空间可以用 ip,此处创建了 ns1 和 ns2 两个命名空间,可以看到只有一个 loopback 的网络设备:
1 | [root@harbor ~]# ip netns add ns1 |
或者使用 nsenter 进入对应的 netns 查看(不要忘记 exit):
1 | sudo nsenter --net=/var/run/netns/ns1 bash |
创建一对虚拟网卡,将 veth pair 一端放入 ns1,另一端放入 ns2:
1 | [root@harbor ~]# ip link add veth1 type veth peer name veth1-peer |
由于初始时网卡状态为 DOWN,需要启用网卡并配置 ip 地址:
1 | [root@harbor ~]# ip netns exec ns1 ip addr add 172.16.0.1/24 dev veth1 |
测试两个 namespace 是否互通:
1 | [root@harbor ~]# ip netns exec ns1 ping 172.16.0.2 |
Veth Pair
“veth devices are virtual Ethernet devices. They can act as tunnels between network namespaces to create a bridge to a physical network device in another namespace, but can also be used as standalone network devices.”
Veth(Virtual Ethernet devices)是 Linux 中通过软件模拟的硬件网卡设备,由于成对出现,也称为 Veth Pair。其实就像一根网线,假设 veth0 和 veth1 是一对 veth 设备,从 veth0 发送数据,那么 veth1 就会收到数据。它常常充当一个桥梁连接着各种网络设备,典型的有:两个 namespace 的连接、Docker 容器之间的连接等,以此构造出各种复杂的虚拟网络。实际上,本机网络 IO 中的 lo 回环设备也是用软件虚拟出来的设备,区别在于 veth 是成对出现的。
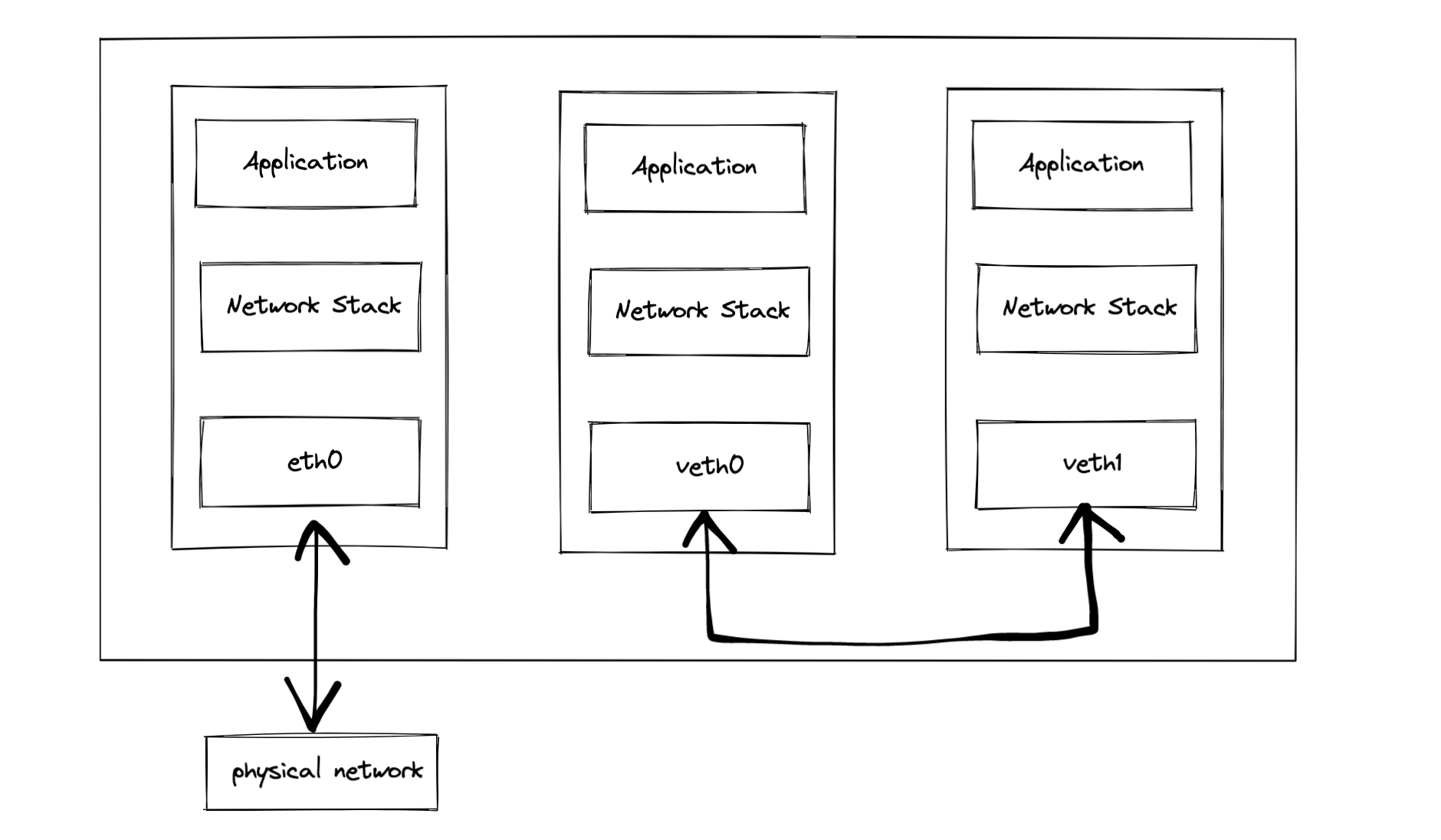
root 与 container 交互:

Linux Bridge
由于简单 veth 互联方案难以做到多个容器的互联,因此采用的是 veth pair + bridge,这也是容器互联经典操作。bridge 是软件模拟硬件交换机,它拥有多个虚拟端口,能将多个虚拟网卡连接在一起,通过自己的转发功能让这些虚拟网卡之间进行通信。bridge 与物理虚拟机类似,有自学习功能,在内存中维护了一张转发表,通过目标 MAC 地址来转发数据包。
需要注意的是 veth 在 bridge 端是不需要分配地址的,因为 bridge 是工作在二层上,只会处理以太包,包括 ARP 解析,以太数据包的转发和泛洪,而不会进行三层(IP)的处理,因此不需要三层的 IP 地址。
路由
如果两个 namespace 处于不同的子网中,就无法通过作用于二层的 bridge 进行连接,只能通过路由器进行三层转发。所谓路由其实很简单,就是选择哪张网卡将数据写进去,至于选择哪张网卡呢,规则在路由表中指定。Linux 拥有多张路由表,最常用的是 local 和 main。
local 路由表统一记录本网络命名空间的网卡设备 IP 的路由规则。
1 | [root@harbor ~]# ip route list table local |
其余基本存在 main 表中,可以用ip route list table local或者route -n看。
除本机外,转发也涉及路由过程,在上文 iptables 中提到,当 Linux 收到数据包发现不是本机的包可以通过查找路由表找到合适的设备将其转发出去。在 ip_rcv 中将包送到 ip_forward 函数中处理,最后在 ip_ouput 函数将包转发出去,整个过程经过了 PREROUTING、FORWARD 和 POSTROUTINE 三个规则。
单主机容器网络问题
有了以上基础,我们可以尝试回答几个问题:
如何虚拟化网络资源,使得容器认为它们每个都拥有专用的网络堆栈?
在 Linux 中,要虚拟化网络资源以使容器认为每个都拥有专用的网络栈,可以通过使用网络命名空间(netns)和虚拟以太网设备(veth)实现。网络命名空间创建了独立的网络栈,每个容器可以与一个网络命名空间关联,从而实现网络隔离。veth 设备成对出现,连接主机的根网络命名空间(root netns)与容器的网络命名空间,使容器在通信时表现得好像拥有独立的网络栈,有效地利用网络资源,确保各个容器之间的网络环境隔离。
如何在容器之间实现隔离与通信,确保良好的容器互操作性?
为了在容器之间实现隔离与通信,我们可以利用 Linux 的网络命名空间(netns)和虚拟以太网设备(veth)。通过网络命名空间,每个容器都可以拥有独立的网络栈,从而实现隔离。然后,使用虚拟以太网设备将这些容器连接到一个虚拟网络交换机(bridge),使它们处于同一以太网段内,实现容器之间的通信。虚拟交换机会转发容器之间的数据包,保证良好的容器互操作性。通过这种方法,我们可以在同一主机上运行多个容器,实现资源共享,并确保它们在隔离的同时能够相互通信。
容器如何与外部网络连接?
为了使容器与外部网络连接,我们需要创建一个虚拟交换机(bridge),并将容器的虚拟以太网设备(veth)连接到该交换机。这样,容器之间可以相互通信,同时也可以通过交换机连接到主机和外部网络。为了实现这一连接,我们需要为交换机分配 IP 地址,并将其设置为容器的默认网关。同时,启用网络地址转换(NAT)功能,以便在容器发送到外部网络的数据包上替换源 IP 地址为主机的外部接口地址,从而使外部网络可以回复数据包给容器。最后,如果需要将容器的某个端口发布到主机的接口上,可以使用 iptables 进行端口转发,将到达主机特定端口的数据包重定向到容器的对应端口。通过这些步骤,我们可以实现容器与外部网络之间的连接,使容器能够与外部服务通信,并让外部网络能够访问容器的特定端口。
总结
本篇文章主要介绍容器网络,从容器网络的演变历史到 Docker 官网的一些描述,再到 Linux 内核网络、网络虚拟化来探究容器的大致底层实现原理,最后回答了单主机容器网络的几个问题。笔者在前一段时间深入学习过 Linux 网络相关知识,本以为容器网络无非是使用到几条命令,官网以及书上的几个简短说明这么简单,在翻阅参考资料与深入学习的过程中,笔者才发现容器网络有着非常庞大且复杂的体系,由于阅历与经验有限,文中多数部分都只是简单介绍就略过了。当然,此篇也只是初探开篇,后续会更深入理解容器网络相关的知识。