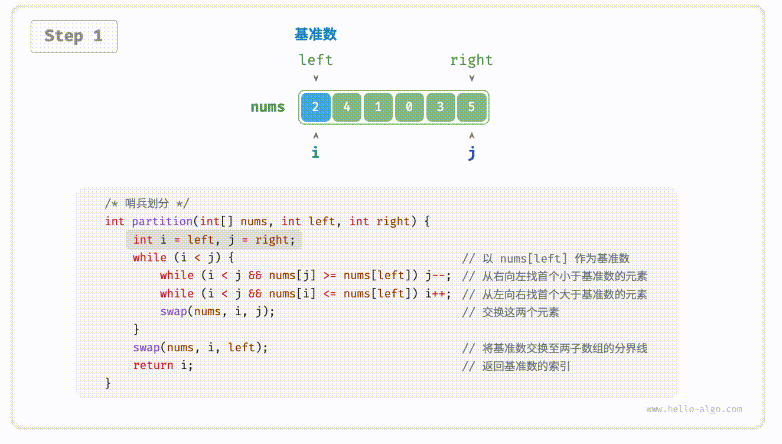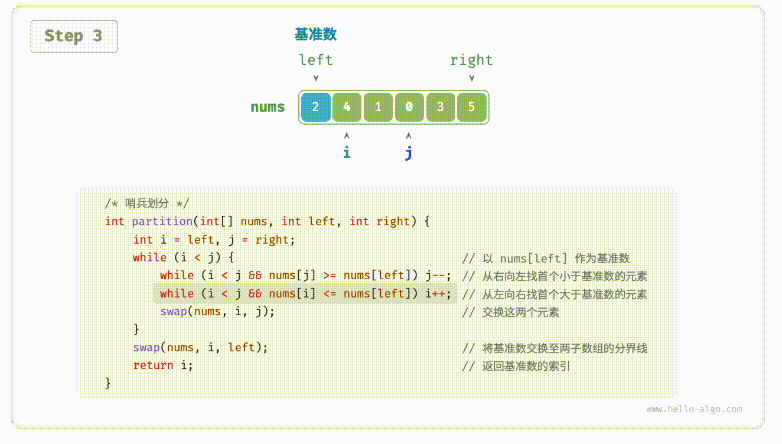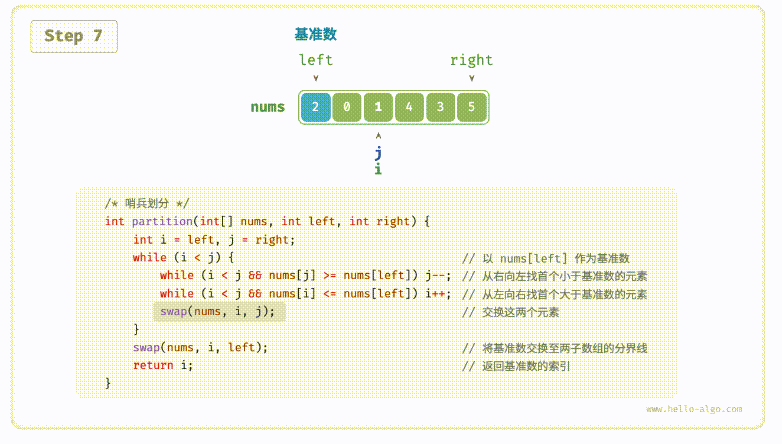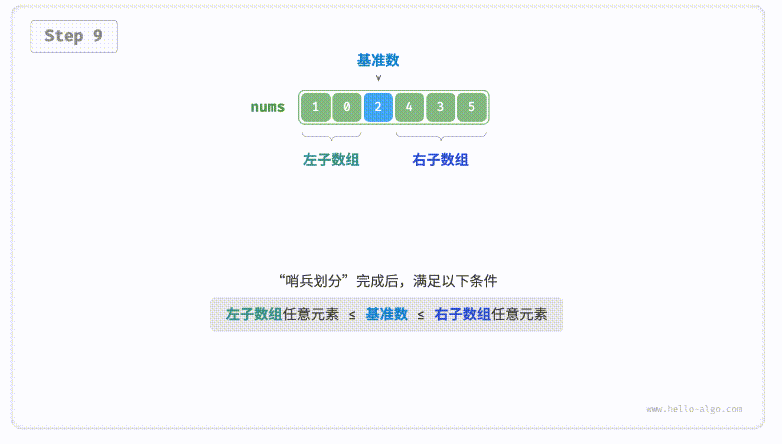
defpartition(nums, left, right): i, j = left, right # 以nums[left]作为基准数 while i < j: while i < j and nums[j] >= nums[left]: # 找到右区间第一个比基准数小的 j -= 1 while i < j and nums[i] <= nums[left]: # 找到左区间第一个比基准数大的 i += 1 nums[i], nums[j] = nums[j], nums[i] # 交换这俩,保证左边都比基准数小,右边都比基准数大 nums[i], nums[left] = nums[left], nums[i] # 将基准数放中间 return i # 哨兵位置
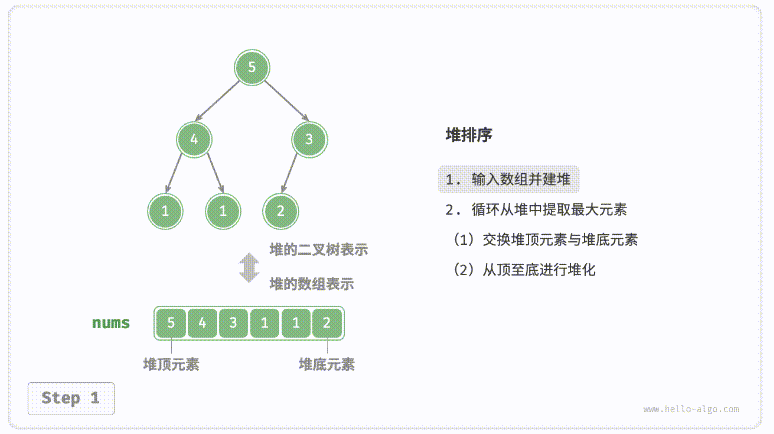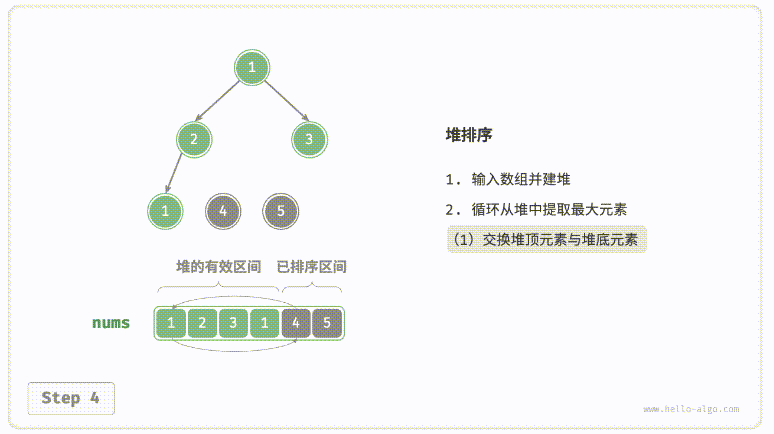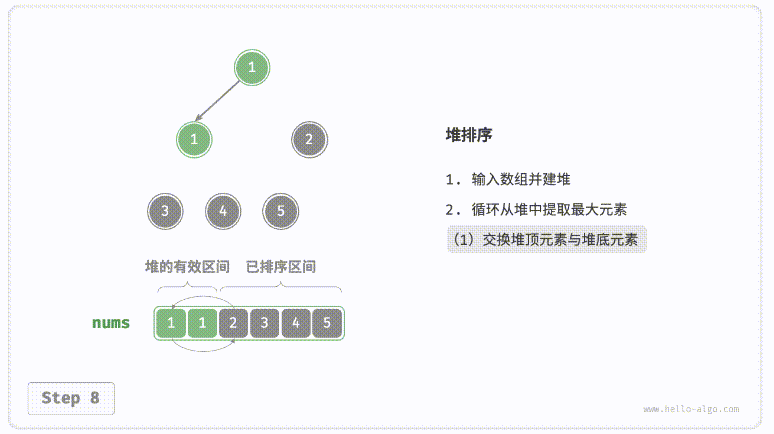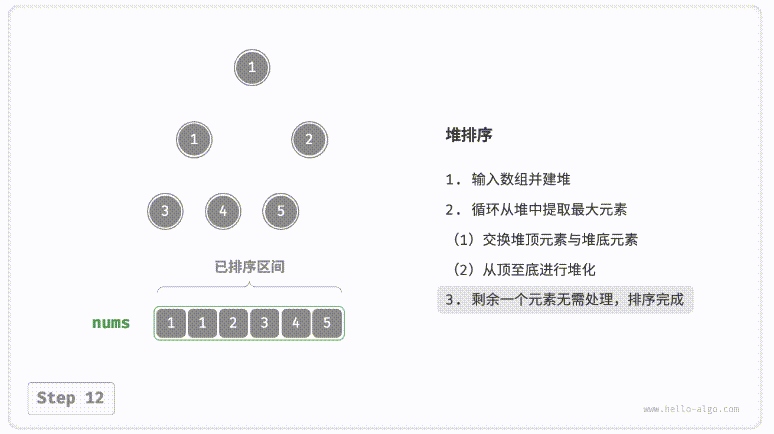
defsift_down(nums, root, k): t = nums[root] # 父节点 while root << 1 < k: # k指堆大小 child = root << 1# 左子节点 if child | 1 < k and nums[child | 1] > nums[child]: # 检查右子节点是否有机会 child |= 1 if nums[child] > t: # 如果当前元素更小,则递归向下,使得堆顶元素更大 nums[root] = nums[child] root = child else: # 如果到了合适的位置,则赋值 break nums[root] = t
nums = [0] + nums # 哨兵,基于此可以通过位运算快速定位子节点以及父节点 k = len(nums)
for i inrange((k - 1) >> 1, 0, -1): # 建堆 sift_down(nums, i, k) for i inrange(k - 1, 0, -1): # 取最大元素与堆底元素交换,并从顶到底调整堆 nums[1], nums[i] = nums[i], nums[1] sift_down(nums, 1, i)
print(nums[1:])
桶排序
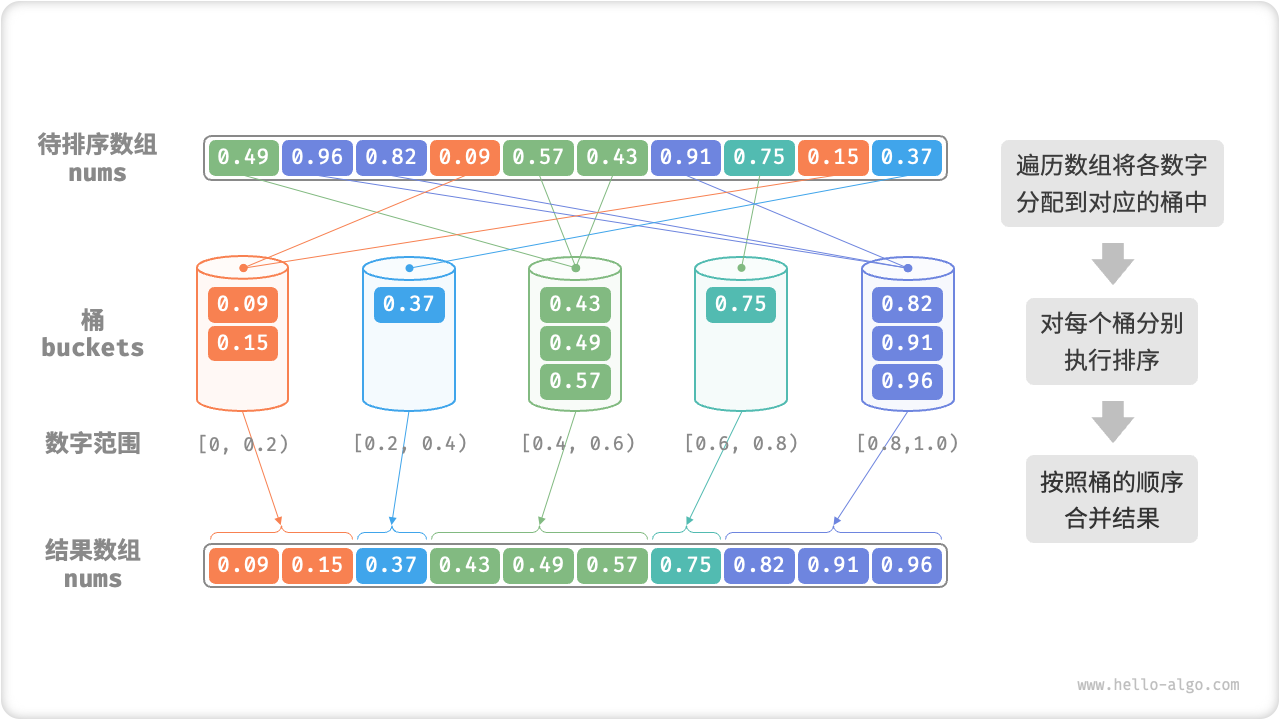
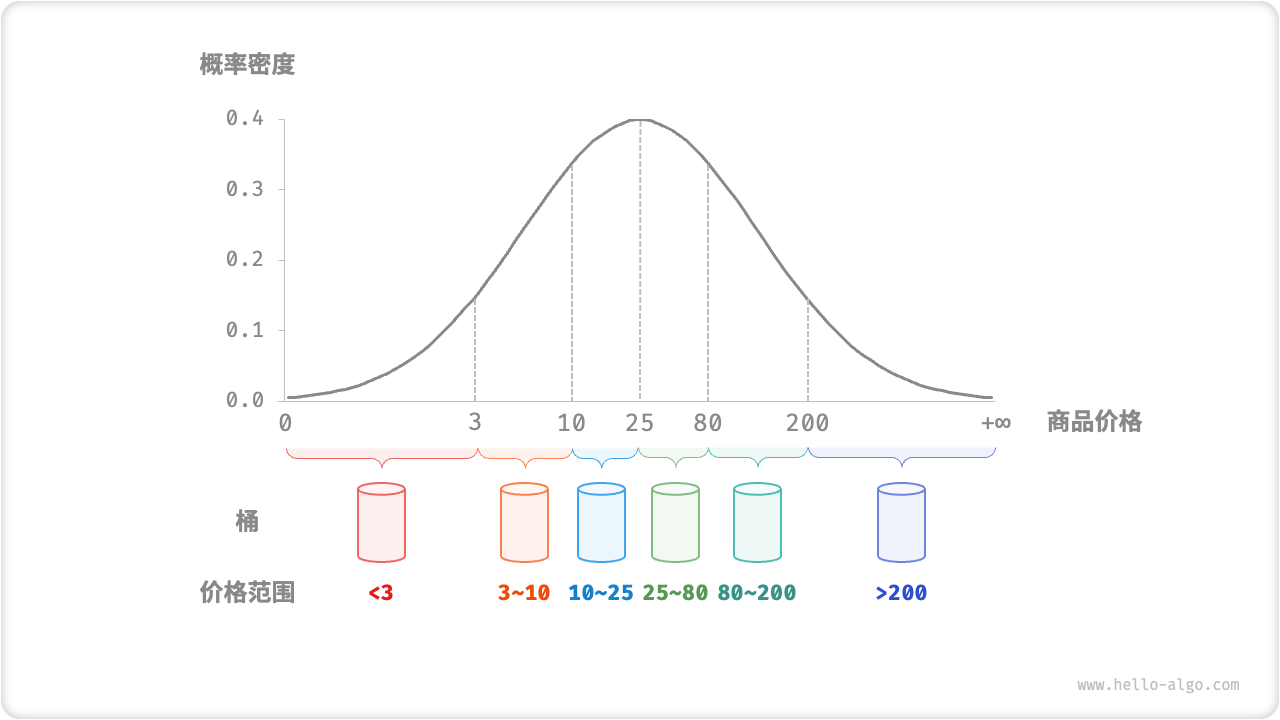
基于分治,非比较的排序算法,通过设置一些具有大小的桶,每个桶对应一个数据范围,将数据平均分散到桶中,然后对桶内执行排序(往往不需要,因为多数只有一个数),最终按照桶范围合并。时间复杂度一般是线性的,n 个数 k 个桶,O(n + k),假设分布均匀,每个桶内元素 O(n/k),排序耗时 O((n/k)log(n/k)),所有桶排序则 O(nlog(n/k))。当桶足够大,分散足够均匀,每个桶一个数,则趋向于O(n)。是否稳定基于桶内排序是否稳定。
流程如下
初始化 k 个桶,将 n 个数分到 k 个桶
k 个桶分别执行排序
从小到大合并 k 个桶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
nums = [56, 32, 13, 26, 43] n = len(nums)
k = 6 bucket = [[] for _ inrange(k)] # 分k个桶 for x in nums: i = x // 10 bucket[i].append(x) for b in bucket: b.sort() i = 0 for x in bucket: for xx in x: nums[i] = xx i += 1 print(nums)
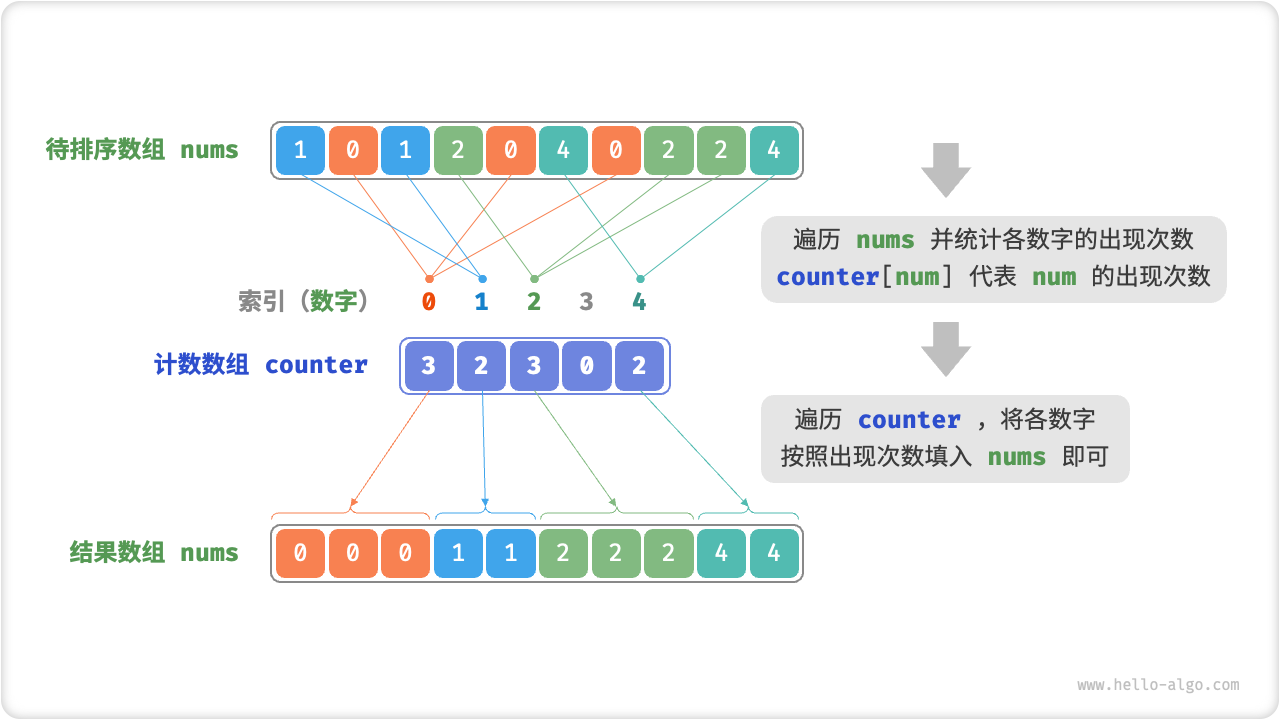
通过统计数量来对元素实现排序,适用于较为密集的数组。时间复杂度O(n + m),包括遍历数组以及计数器。一般 n >> m,趋近于 O(n)。通过倒序遍历可以避免修改元素之间的相对位置,正序则非稳定。
流程如下
遍历数组找到最大数 m,创建一个 m+1 辅助数组
遍历数组计数
编辑计数器统计出现次数,填充即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14
nums = [5, 3, 1, 2, 4, 3, 2, 1] n = len(nums)
maxx = max(nums) c = [0] * (maxx + 1) for x in nums: c[x] += 1 idx = 0 for i, x inenumerate(c): # 遍历计数器 while x > 0: # 递减计数器 nums[idx] = i # 填充nums x -= 1 idx += 1 print(nums) # [1, 1, 2, 2, 3, 3, 4, 5]