一文了解容器技术
容器的实质是隔离了外界,限制了资源的特殊的进程
进程的静态表现是程序,存储在磁盘中。进程的动态表现是程序执行起来后,计算机内存中的数据、寄存器中的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。
借用 Docker Getting Started 的一句话:简单来说,容器就是机器上的另一个进程,它与主机上所有其他进程隔离开来,这种隔离利用了 kernel namespaces 和 cgroups,这些 features 在 Linux 中已经存在很长时间了,但是 Docker 的出现使得这些功能变得平易近人且易于使用。
容器技术的核心功能就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”,容器就是一个单进程模型。
1 | $ docker run -it busybox /bin/sh |
Cgroups
Linux Cgroups 的全称是 Linux Control Group,它是容器技术中用于限制资源的主要手段,它能够限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等,也能够执行对进程优先级设置、审计、将进程挂起和恢复等操作。
实际上,Cgroups 就是一个子系统目录加上一组资源限制文件的组合。在 Linux 中,Cgroups 暴露出来的操作接口是文件系统,以文件和目录的方式组织在/sys/fs/cgroup路径下,可以通过mount -t cgroup将他们展示出来。输出结果是一系列文件系统目录(CPU、块设备 I/O 限制 blkio、独立 CPU 核和对应的内存结点 cpuset、内存使用的限制 memory),这些都叫子系统,是本机可以被 Cgroups 进行限制的资源种类。
每类资源对应的子系统也叫 resource controller,如管理 cpu 的是 cpu controller,管理内存的是 memory controller。
笔者使用的虚拟机是 Ubuntu22.04,使用的是 cgroup v2。cgroup v2 是 Linux cgroup API 的下一个版本,提供了一个具有增强资源管理能力的统一控制系统,对 cgroup v1 进行了多项改进。
我们先来看看 cgroup v1 的目录树结构:
1 | $ cd /sys/fs/cgroup |
可以看到,在/sys/fs/cgroup 下面有很多诸如 cpuset、cpu、memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,可以看到该类资源具体可以被限制的方法。比如说 cpu:
1 | $ ls /sys/fs/cgroup/cpu |
这个目录就称为一个控制组,需要使用该配置文件的话就要在对应的子系统下面创建一个目录,Linux 会自动生成该子系统对应的资源限制文件。只需要修改这些文件的内容就可以添加相应的资源限制。其中 tasks 文件记录了此 cgroup 所包含 task 的 PID 列表,把某个线程的 PID 加到这个文件中时,就等同于把该线程移到此 cgroup 下。cgroup.procs 则包含了此 cgroup 所包含的子 cgroup 列表,操作方法与 tasks 文件一样。
接下来看看 cgroup v2 的目录树结构:
1 | $ ls /sys/fs/cgroup |
与 cgroup v1 不同的是,在这个新增的 cgroup 内已经有了多种子系统可以用来控制位于其中的 task,可以看到 cpu,memory…等的子系统组信息都自动产生,而不是像 v1 想要使用不同的 system 就必须切换到不同的文件夹中建立相应的 cgroup。如上述的 v1 中的范例中,要想管理 memory 的话,就得去 memory 的 cgroup 文件夹下新增子 cgroup。
1 | $ cat cgroup.controllers |
通过 cgroup.controllers 文件就可以知道,例如下面显示出有 cpuset,cpu,io…等子系统;而 v1 用于记录线程 PID 的 tasks 文件就等同于 v2 的 cgroup.procs;用于记录子 cgroup 的 cgroup.procs 就等同于 cgroup.threads。
cgroups 中不同子系统要控制的资源有很多东西可以讨论,限于篇幅,更具体的信息这里不再赘述,读者可以参考文末推荐阅读继续深入学习。
Cgroups 也存在对资源限制能力不完善的问题:
- 在容器内执行 top 指令显示的信息是宿主机的 CPU 和内存数据
/proc 文件系统记录了当前内核运行状态的一系列特殊文件,可以通过访问这些文件来查看系统以及当前运行进程的信息,如 CPU 使用率、内存占用率等。容器内部缺省挂载了宿主机上的 procfs 的/proc 目录,其包含如:meminfo,cpuinfo,stat,uptime 等资源信息。一些监控工具如 free/top 等还依赖上述文件内容获取资源配置和使用情况。当它们在容器中运行时,就会把宿主机的资源状态读取出来,引起错误和不便。
解决这个问题的方法是使用 lxcfs,把宿主机的/var/lib/lxcfs/proc/memoinfo 文件挂载到 Docker 容器的/proc/meminfo 位置后。容器中进程读取相应文件内容时,LXCFS 的 FUSE 实现会从容器对应的 Cgroup 中读取正确的内存限制。从而使得应用获得正确的资源约束设定。
Namespace
Namespace 是 Linux 在 2.4.19 中引入的一个 feature,它的 idea 是将某些全局系统资源包裹在一个抽象层中,使得 namespace 中的进程看起来像是拥有自己资源的孤立实例。
它是容器技术中用来修改进程视图(隔离资源)的主要方法,对隔离应用的进程空间做了隔离限制(比如说 pid=1),每个 namespace 中的应用进程都看不到宿主机里真正的进程空间,也看不到其他 namespace 的具体情况。
Namespace 其实是通过 Linux 中创建新进程方法 clone() 中的 CLONE_NEWPID 参数来指定创建的。clone() 可以创建一个新的子进程,它执行方式与 fork() 类似,但是与 fork() 不同的是,clone() 允许子进程与调用进程共享其执行环境的一部分,例如内存空间、文件描述符表、信号处理程序表等,可以通过传递不同 namespace 的标志来为子进程创建新的命名空间。
1 | int pid = clone(main_function, stack_size, SIGCHLD, NULL); |
Docker 在启动的时候会默认启动 6 个 namespace:包括 mnt、pid、net、ipc、uts 和 user。主要修改的视图资源如下:
- Uts:主机名和域名隔离
- Ipc:信号量,消息队列和共享内存隔离
- Mnt:文件系统挂载点隔离
- Net:网络设备、网络栈、端口等隔离,每个 namespace 都有自己独立的 ip,路由和端口
- Pid:进程编号
- User:用户与组
每个进程的每种 namespace 都以文件的形式存储在宿主机中,每个 namespace 都在对应的/proc/{pid}/ns下有一个对应的虚拟文件,并且链接到一个真实的 namespace 文件。
通过这种方式,可以选择加入某个进程已有的 namespace 中,达到进入这个进程所在容器的目的,即 docker exec 的实现原理,该操作依赖的是一个叫setns()的 Linux 系统调用,它将调用线程与提供的命名空间文件描述符重新关联,常用于加入一个现有的 namespace。
当一个进程加入到另一个 namespace 中,宿主机上的 namespace 会有所体现,比如创建的一个 bash 进程,加入了一个容器进程的 network namespace,该 bash 进程看到的网络设备会和在容器中看到的网络设备一样,即网络设备视图被修改了。
因此也可以说,docker exec 指令每次执行都会新创建一个和容器共享 namespace 的进程。
此外,Docker 还专门提供了一个参数,可以启动一个容器并将其“加入”到另一个容器的 network namespace 中,即-net。
1 | docker run -it --net container:4ddf4638572d busybox ifconfig |
如果指定-net=host,意味着这个容器不会为进程启用 network namespace,这个容器进程会和宿主机上其余的普通进程一样直接共享宿主机的网络栈。这为容器直接操作和使用宿主机网络提供了一种方式。
基于 Linux Namespace 的隔离机制相比于虚拟化技术而言,隔离得并不彻底:
- 容器只是运行在宿主机上的一个特殊的进程,多个容器共享宿主机的内核。
- 在 Linux 内核中,很多资源和对象是不能被 namespace 化的,比如时间,一旦一个应用程序使用系统调用修改了时间,那么整个宿主机的时间都会被修改。
因此基于虚拟化或独立内核技术的容器实现可以更好地在隔离与性能之间做出平衡。
容器镜像 - 基于 rootfs 的文件系统
即使开启了 Mount Namespace,容器进程看到的文件系统也跟宿主机完全一样。
Mount namespace 修改的是容器进程对文件系统挂载点的认知,只有在挂载操作发生之后,进程的视图才会被改变,此前,新创建的容器直接继承宿主机的各个挂载点。只有伴随挂载操作才能生效。这里可以通过通知容器进程需要挂载的目录来解决,只需要在容器进程启动之前,执行一句挂载语句:
1 | mkdir -p $HOME/test |
Linux 的 chroot 命令也可以解决这个问题,实质上是通过改变进程的根目录到指定位置来解决。
而 namespace 就是基础 chroot 改良发明的。构建一个容器时,一般会在容器根目录下挂载一个完整的文件系统,容器启动后就能查看宿主机的所有目录和文件。
这个挂载在容器根目录上用于为进程提供隔离后执行环境的文件系统就是所谓的容器镜像。专业名字叫 rootfs(根文件系统),常用的 rootfs 会包括/bin、/etc、/proc 等目录和文件,但是不包括操作系统内核。
核心原理如下:
- 启用 Linux Namespace 配置
- 设置指定 Cgroups 参数
- 切换进程的根目录(优先使用 pivot_root 系统调用,不行再执行 chroot)
尽管有着容器与宿主机共享一个内核的缺陷,但是正是由于 rootfs 的存在,容器才有了一致性:
- rootfs 里打包的不仅是应用,而是整个操作系统的文件和目录,意味着应用以及它运行所需要的所有依赖都被封装在了一起。
- 深入到操作系统级别的运行环境一致性打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
Docker 在镜像设计中,引入了层的概念:用户制作镜像的每一步操作都会生成一个层,也就是增量的 rootfs。其中用到了一种叫联合文件系统(Union File System)的功能:将多个不同位置的目录联合挂载到同一个目录下,即多个目录下的文件合并到一个目录中。
ubuntu 默认使用的联合文件系统的实现是 AuFS(Advance UnionFS),关键目录结构在/var/lib/docker 路径下的 diff 目录:
1 | $ docker image inspect ubuntu:latest |
从上述输出中可以看到,Docker 容器存在五个层,使用镜像的时候会将它们联合挂载到一个统一的挂载点上(/var/lib/docker/aufs/mnt/)。而目录下则是一个完整的 ubuntu os。
关于镜像层被联合挂载到文件系统的信息记录在AuFS的系统目录/sys/fs/aufs下。可以通过查看AuFS挂载信息找到目录对应的AuFS的内部ID(si),然后使用这个ID,可以在/sys/fs/aufs下查看各个层的信息。
1 | 获取si |
从信息中能够看到,镜像层都放在/var/lib/docker/aufs/diff 目录下,然后被联合挂载到/var/lib/docker/aufs/mnt 路径下。
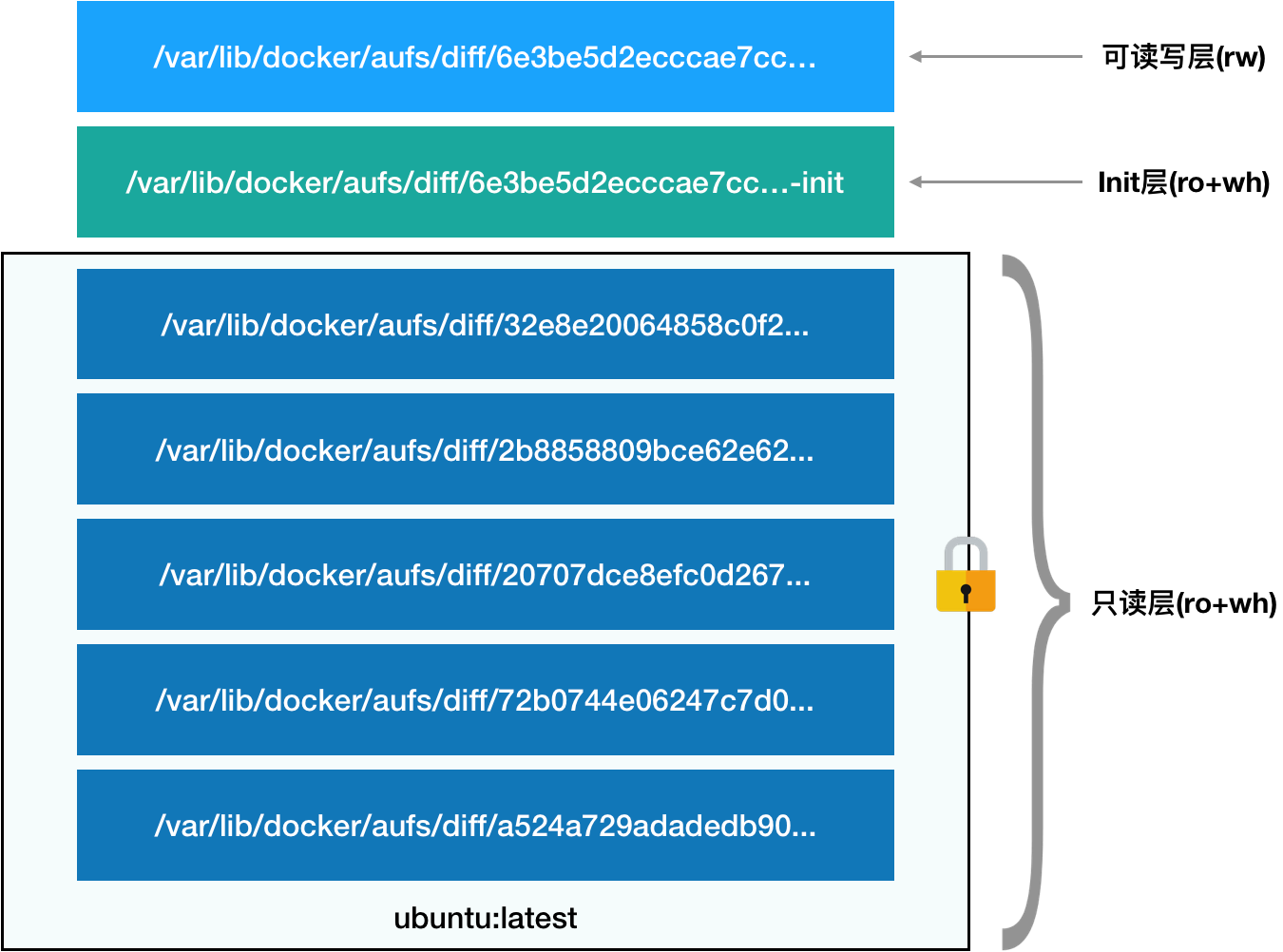
rootfs 由以下三部分构成:
- 可读写层(容器层)
容器 rootfs 最上层的部分,挂载方式为 rw(可读写)。没写入文件前为空,进行写操作后,修改的内容会以增量的方式出现在该层中。如果要实现删除操作,AuFS 会在这层创建一个 whiteout 文件,将只读层的文件遮挡起来。
比如,如果想要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读+whiteout的含义。
- Init 层
以-init 结尾,加载只读层和读写层之间。是 Docker 项目单独生成的一个内部层,用于存放/etc/hosts/etc/resolv.conf等信息。
Init 层使得用户在对当前容器的修改(hostname 等)以一个单独的层挂载出来,只对当前容器有效,用户执行 docker commit 的时候只会提交可读写层,不包含这些层的内容。
- 只读层(镜像层)
只读层是 rootfs 最下层的 x 层,对应的是镜像的 x 层,挂载方式都是只读的(ro+wh,readonly+writeout)。这些层以增量的方式分别包含了 ubuntu os 的一部分。
由于 Docker 的镜像只是一个 os 的所有文件和目录,不包含内核,最多几百兆,因此与传统 vm 的快照镜像不同。
如何在容器里修改 Ubuntu 镜像的内容?
容器中所有的增删改查都只会作用在容器层,相同的文件上层会覆盖掉下层。因此在修改一个文件的时候,会从上到下层查找是否存在这个文件,如果找到了就复制到容器层,修改,修改的结果就会作用到下层的文件,即 copy-on-write(写拷贝)。
Docker commit
在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成一个新的镜像。只读层在宿主机上是共享的,不会占用额外的空间,这也是写拷贝机制。但是由于 Init 层的存在,避免了docker commit 将堆当前容器的一些修改(/etc/hosts 等)一起提交掉。
Volume 机制
容器里进程新建的文件,怎么才能让宿主机获取到?
宿主机上的文件和目录怎么才能让容器里的进程访问到?
Volume 机制允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。有以下两种两种声明方式:
1 | # 将宿主机指定目录挂载到容器内/test目录 |
在 chroot 执行之前,容器进程一直可以看到宿主机上的整个文件系统。因此只需要在 rootfs 准备好之后,执行 chroot 之前,将 Volume 指定的宿主机目录(/home)挂载到指定的容器目录(/test)在宿主机上对应的目录(/var/lib/docker/aufs/mnt/{可读写层 id}/test)
在执行挂载操作的时候容器进程已经创建了,Mount Namespace 已经开启了,这个挂载事件只在容器内可见,宿主机上无法看到容器内部的这个挂载点,这保证了容器的隔离性不会被 Volume 打破。
注意:这里提到的”容器进程”,是 Docker 创建的一个容器初始化进程 (dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。
dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。
最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
Volume 机制使用的挂载技术是 Linux 的绑定挂载(bind mount)机制,它允许将一个目录或者文件挂载到一个指定目录上,并且在该挂载点上进行的任何操作,都只是发生在被挂载的目录或者文件上,原挂载点的内容会被隐藏起来不受影响。简单来说,挂载就是一个 inode 替换的过程,只是改变了 dentry 指针的指向。

由于 docker commit 是发生在宿主空间中的,因此对于容器内绑定挂载的存在并不知情,不过由于新建目录的操作不是挂载操作,所以还是会创建一个空的文件夹。

总结
本文以 Docker 为例,简述了容器技术实现的基本原理:通过 Cgroups 来制造约束,通过 Namespace 来修改进程视图,从而为这个特殊的进程创造出一个边界。然后我们还通过 rootfs 了解到了容器镜像的相关概念,当允许一个容器时,会使用一个隔离的文件系统,它就是由容器镜像提供的,这个镜像包含了运行应用程序所需的一切,还包含了容器的其他配置如环境变量、运行的默认命令等。我们甚至可以将容器看做是 chroot 的一个扩展版本,文件系统只是来自于镜像,而容器则增加了额外的隔离功能,这在单纯使用 chroot 时是无法实现的,这就是为什么容器技术更易于使用的原因之一。




