一文了解 OS-内存布局
揭开操作系统内存的面纱
众所周知,每个程序都有属于它自己的源程序,通过翻译、链接阶段可以得到它的 ELF 可执行目标文件。ELF 可执行目标文件则是将这个程序的代码和数据按照一定的格式组织在这个文件中,其中包含了段头部表、ELF 头、节头部表和若干的节(section)。在 ELF 文件中,会为这个文件的每一条指令和数据分配一段虚拟地址,在加载 ELF 文件时,按照虚拟地址的大小来组织就能得到一个虚拟地址空间的布局。

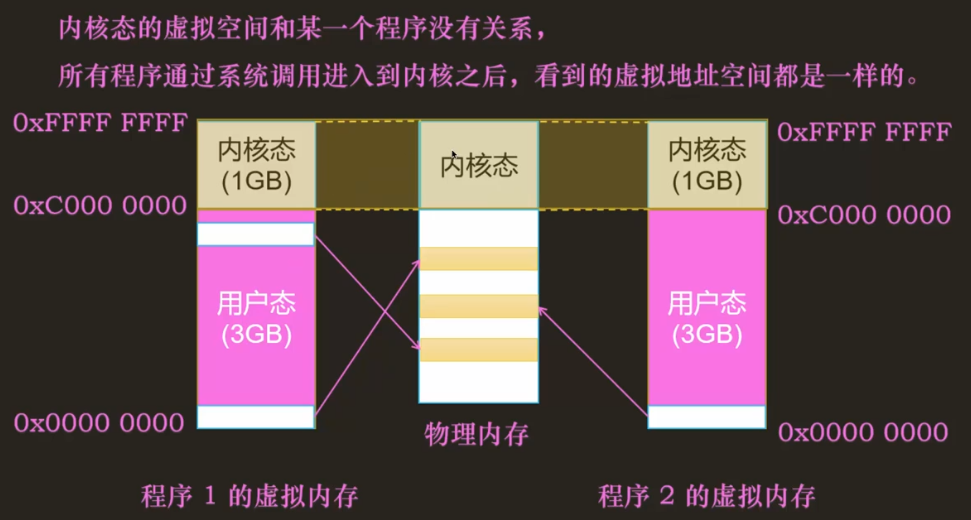
当存在多个程序时,由于它们的ELF 可执行目标文件里的虚拟地址都是一样的,因此它们自己的虚拟地址空间的范围都是从 0 到虚拟内存的最大值,这便是虚拟内存的作用之一,隔离程序内存。不同的是它们的指令和代码都不一样,因此对于一模一样的虚拟地址空间而言,其使用情况不一样。当程序运行时,只需要将 ELF 可执行目标文件加载到物理内存中,此时只需要加载使用到的指令和数据(按需加载),因此尽管物理内存不大,操作系统却可以在内存中同时维护着多个程序。对于物理内存地址和虚拟内存地址的映射维护,则交由页表来管理。
总而言之,虚拟内存其实是不可见的,虚拟内存中的虚拟地址只是一个存在于物理内存上的值,通过页表映射到实际使用的物理内存中,为程序分配虚拟地址时只是赋予其虚拟地址的值而已,并没有真正为程序分配(物理)内存。在页表初始化的时候,虚拟地址对应到的物理页号都是不知道的,此时页表中的有效位都为 0。当要访问一段虚拟内存地址时,那么需要将该虚拟地址压入 eax 寄存器,CPU 去 TLB 中查找,发现没有,再去页表中查找,如果页表中对应项没有物理页号,则会产生缺页异常,然后通过调用缺页异常处理程序获取一个空闲的物理页,分配给需要访问的虚拟页对应的页号。然后,CPU 会再次执行一次指令,这次指令的执行就能够正确访问到对应的物理内存了。
虚拟内存布局
对于 32 位操作系统而言,虚拟地址空间大小共有 2^32 = 4G,而对于 64 位操作系统而言,虚拟地址空间大小共有 2^64 = 16,777,216TB。这里需要明确一下,内存是以字节为单位存储的,无论是虚拟地址还是物理地址都对应的是一个字节。
一个程序运行的时候,可能会处于用户态或者内核态,但不管是运行在用户态还是运行在内核态,都需要使用虚拟地址,这个是由于硬件决定的,计算机访存的时候都会经过地址转换(内存管理单元 MMU)来获得最终的物理地址,操作系统作为软件需要服从硬件的决定。
32 位系统中,一般内核态与用户态的占比为 1:3,这意味着 4G 的总虚拟内存中,内核态占 1GB,用户态占 3GB。每个用户程序都使用相同的虚拟地址空间 0x0 ~ 0xFFFFFFFF,其中内核程序使用虚拟地址空间:0xc0000000 ~ 0xFFFFFFF。内核程序的虚拟地址空间和任意一个程序都无关,所有程序通过系统调用进入到内核之后,看到的虚拟地址是一样的,虽然应用程序看到的虚拟地址也是一样的,但是内容不一样,而内核程序的话看到的就是内容也是一样的,这意味着所有程序的内核态共享一个虚拟地址空间。
为什么维护了内核页表,还要将内核页表拷贝到程序页表中?
主要是为了提高性能,当一个程序通过系统调用陷入内核态时,就不需要再切换页表了(切换页表需要消耗性能,比如刷新 TLB 页表项缓存),这是一种空间换时间的设计。
在 64 位系统中,一般只用到 48 位(256T),其中内核态使用 128T,用户态用 128T,中间是一堆操作系统不会去使用的内存空洞。内核态地址(0~46 位任意,47~63 全是 1),用户态地址(0~46 位任意,47~63 全是 0),其中用户态顶部界限为 TASK_SIZE=0x0000 7FFF FFFF FFFF,标志着用户态的最大空间。

用户态虚拟内存布局
由于 32 位与 64 位用户态虚拟内存布局类似,以下则不分 32 位与 64 位讨论。
用户态虚拟地址空间存储的内容从高地址到低地址大致有如下几点:
- 栈:存放函数调用时的参数、返回值、局部变量等信息,从高地址向低地址增长,可读写且私有。动态,高地址往低地址增长。rsp 是指向栈顶的指针,存储在 RSP 寄存器中。
栈为什么要由高地址向低地址扩展?
- 为了避免栈空间和代码段冲突,防止缓冲区溢出
- 便于确定栈空间的起始地址
- 可以使堆和栈能够充分利用空闲的地址空间。有些程序用堆多,有些用栈多,很难确定栈和堆的分界线
- 历史原因:在没有 MMU 的时代,为了最大的利用内存空间,堆和栈被设计为从两端相向生长。那么哪一个向上,哪一个向下呢?人们对数据访问是习惯于向上的,比如你在堆中 new 一个数组,是习惯于把低元素放到低地址,把高位放到高地址,所以堆向上生长比较符合习惯,而栈则对方向不敏感,一般对栈的操作只有 PUSH 和 POP,无所谓向上向下,所以就把堆放在了低端,把栈放在了高端。但现在已经习惯这样了。
- mmap 内存映射区:存放文件映射到内存的区域,如 mmap 等函数创建的映射区域或动态链接库等,可读写或只读且共享或私有。从高地址往低地址增长。mmap_base 指针指向了内存映射区的基地址。
为什么从高地址往低地址增长?
- 32 位用户态只有 3GB,从低地址往高地址增长的话,堆用的内存空间可能就只有很少一部分,但是对栈来说,栈一般占的都很少,一般固定栈大小为 10MB,基本够用了,如果栈有界,可以在栈末尾端安置内存映射区,就能从高地址往低地址增长了。
- 为了兼容历史上的驱动程序,低地址被分配给物理内存使用,高地址被分配给 Memory map IO(内存映射输入输出)。因此,当物理内存不足时,就只能从高地址开始分配 mmap 内存映射区。
- mmap 内存映射区通常用于加载大文件或共享内存等场景,如果从低地址开始分配,可能会导致虚拟地址空间的碎片化。而从高地址开始分配,则可以避免这种情况。
- 对于 64 位来说,往哪边增长都一样,两种内存布局都存在。反正空间大小足够。
- 关于内存映射区,可以移步博文一文了解 os-内存映射了解。
- 运行时堆 (heap):存放动态分配的内存,如 malloc 等函数申请的内存,从低地址向高地址增长,可读写且私有。
- 未初始化数据 (.bss):存放未初始化的全局变量和静态变量,初始值为 0 或 NULL,可读写且私有。
- 已初始化数据 (.data):存放已初始化的全局变量和静态变量,可读写且私有。
- 代码 (.text) 存放可执行文件中的代码,通常位于低地址处,只读且共享。

内核态虚拟内存布局
与用户态不同,在 32 位系统与 64 位系统的局部差别就比较大,主要因为32 位内核态空间太小了,因此后文会区分 32 位与 64 位,分开讨论。
在 32 位系统下,我们知道内核态占了 1GB,用户态占了 3GB,中间通过 PAGE_OFFSET(TASK_SIZE)分隔开。
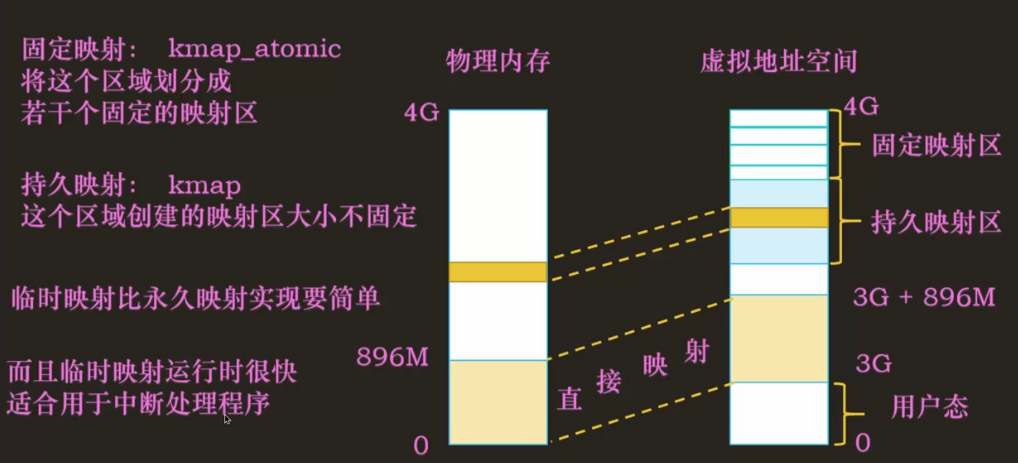
内核态的前 896M 是直接映射区,用于存放内核代码、数据和程序相关的数据结构,比如页表、用户态的虚拟地址空间结构 mm_struct、vm_area_struct 等。接下来是 vmalloc 区,用于内核映射,申请不连续的物理内存(堆内存),使用 vmalloc() 申请,从 VMALLOC_START(低地址)到 VMALLOC_END(高地址)。在 vmalloc 区域与直接映射区之间有个 8M 的安全区,用于捕获对内存的越界访问。基本每两个相邻的区之间都会有。再接下来是持久映射区,从 KMAP_BASE(低地址)到 FIXADDR_START,用于内核永久内存映射。然后是固定映射区,用于内核临时映射,到 0XFFFF FFFF。
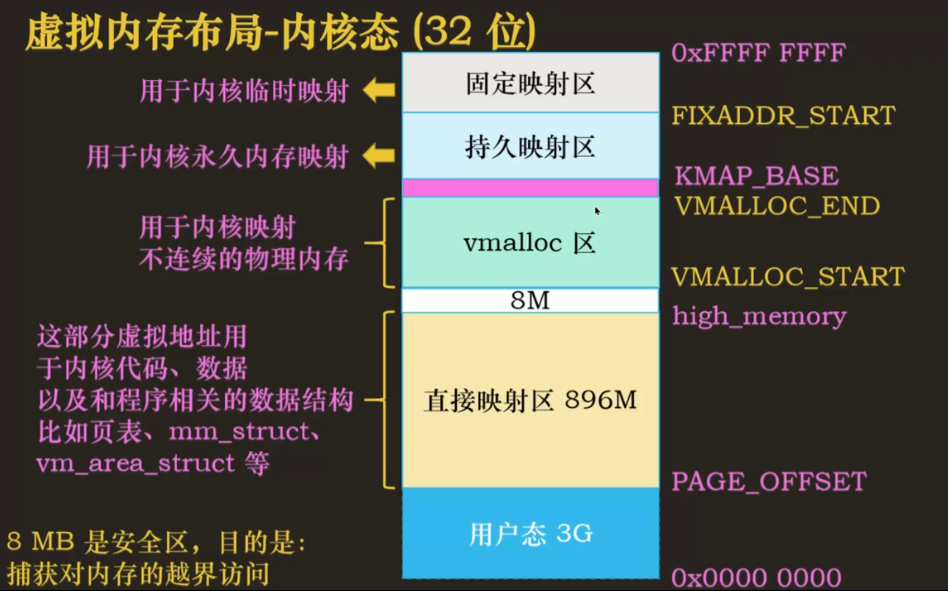
直接映射区的命名由来是该区域与物理内存之间只是简单的直接映射关系,该区域对应的物理内存区域是从 0 地址到 896M 的区域,虚拟地址只用减去特定偏移即可获取到对应的物理地址,比如我获取到直接映射区的一个虚拟地址,只需要简单的计算,如减去 PAGE_OFFSET,即可得到对应的物理地址。那么内核访问直接映射区也需要经过地址转换吗?答案显而易见,内核程序只能服从于硬件要求。
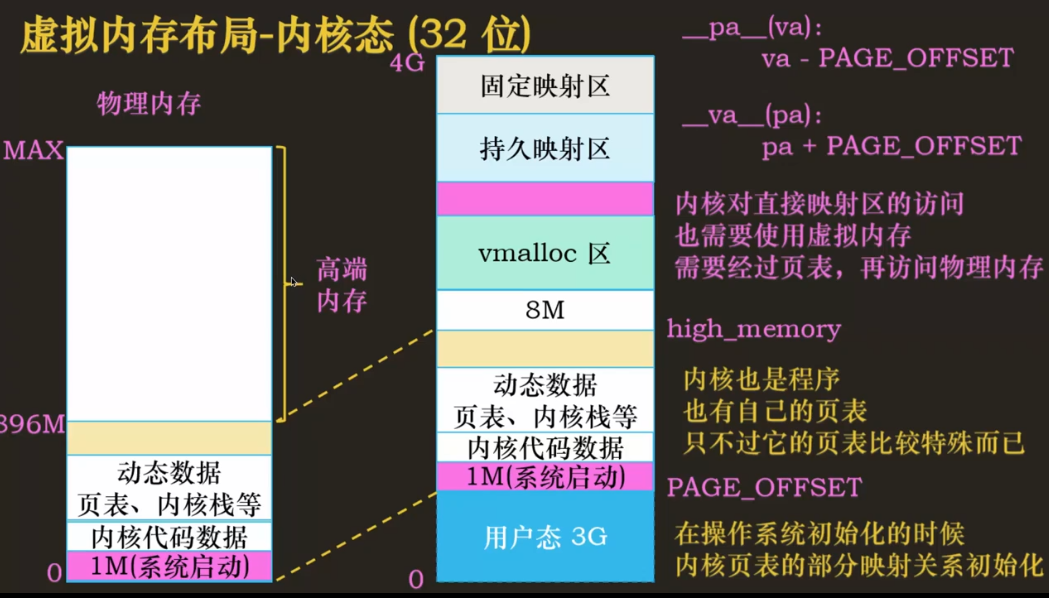
下面我们来了解一下高端内存这个概念,它是 32 位系统有,而 64 位系统没有的。高端内存是直接映射区高地址邻接点以上的区域,即分布在 896M 以上的物理内存区域,是只属于物理内存的概念。用户态的内存可以直接映射到高端内存上,但是没法访问直接映射区(前 896M),而内核态的内存却可以访问所有的物理内存。由于直接映射区已经映射了内核态虚拟地址空间的 896M,内核态的虚拟地址只剩下 120M,那么内核态该如何访问所有的高端内存?
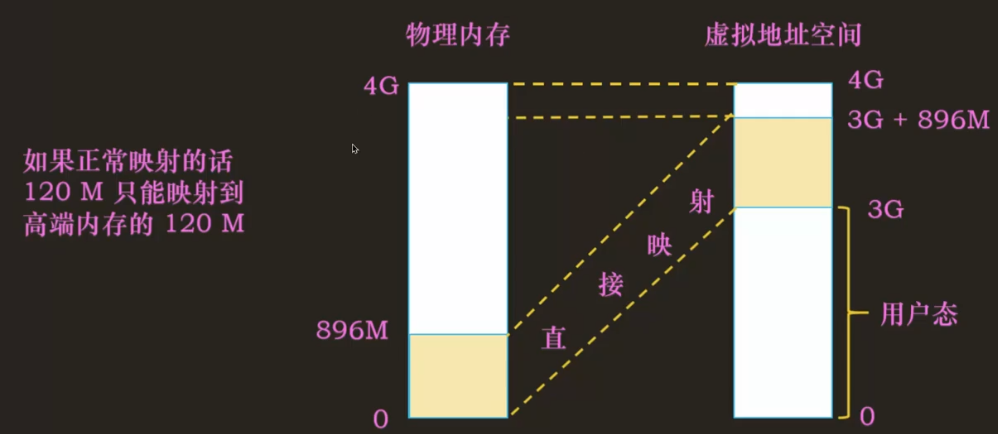
如果是正常映射的话只能映射到高端内存的 120M,我们可以使用持久映射、固定(临时)映射、vmalloc。
- 固定映射:
- 拿 120M 的一部分做映射,要哪块的时候就建立映射,要访问其他的时候就删除映射,映射另一块区域(相同虚拟地址段在不同时刻映射不同的物理内存区域)
- 对于固定映射而言,将这个区域划分为若干固定的映射区域,每个映射区域映射不同的物理内存区域,用完了直接删除映射关系即可。可以用 kmap_atomic()。
- kmap_atomic() 是用于建立临时内存映射的函数,它映射到固定映射区(Fixing Mapping Region)。它用于紧急的,短时间的映射,没有使用任何锁,完全靠一个数学公式来避免混乱。它空间有限且虚拟地址固定,这意味着它映射的内存不能长期被占用而不被 unmap。kmap_atomic() 在效率上要比 kmap() 提升不少,然而它和 kmap() 却不是用于同一场合的。kamp_atomic() 的使用场景如下:
- 在内核进入保护模式之前,要先建立一个临时内核页表并开启分页功能,这个临时页表用于映射相应的内存。
- 在中断处理程序中,使用 kmap_atomic() 和 kunmap_atomic() 函数来创建和销毁临时映射区间,这个区间用于映射高端内存。
- 持久映射:
- 与固定映射不同的是,这个区域创建的映射区域大小不固定。可以通过 kmap()
- kmap() 主要用于文件系统、网络等对高端内存访问有较高性能要求的模块中。
- 临时映射比持久映射的实现要简单,临时映射运行也快,适用于中断处理程序。但是临时映射的窗口很少(固定分了几块而已)。
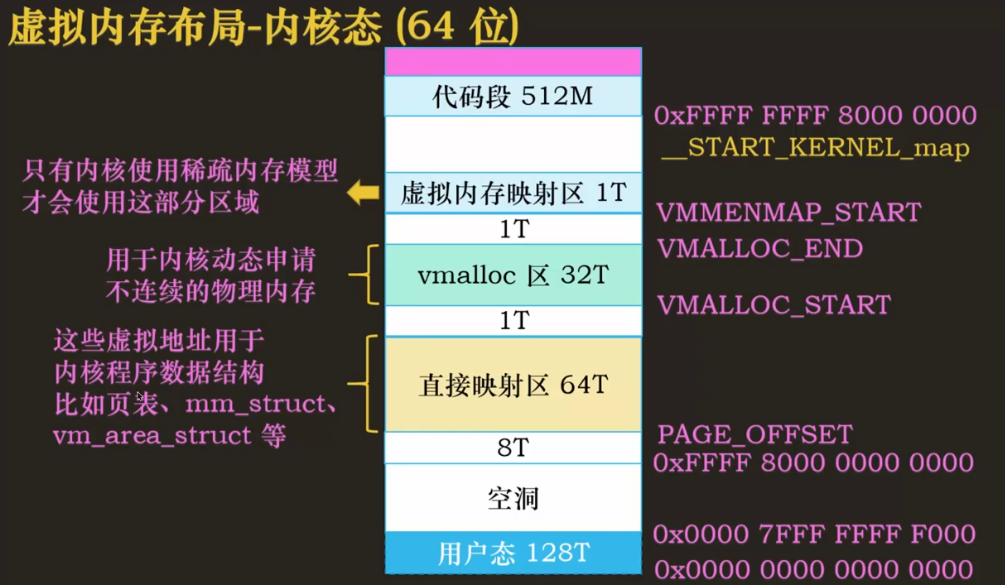
64 位的内核态虚拟内存布局就简单许多,因为它的空间大,足够映射所有的物理内存。
前 8T 是空洞(作为保护作用),PAGE_OFFSET,从 PAGE_OFFSET 开始是 64T 的直接映射区,用于内核程序数据结构,如页表、mm_struct、vm_area_struct 等。然后是 1T 空洞,从 VMALLOC_START 到 VMALLOC_END,中间是 32T 的 vmalloc 区,用于内核动态请求不连续的物理内存,再是 1T 空洞到 VMMENMAP_START,到虚拟映射区 1T,只有内核使用稀疏内存模型的时候才会用到这块区域。然后是一大波空洞,到临界点__START_KERNEL_map,后面是 512M 的代码段,没放到直接映射区中,但是通过直接映射的方式映射到物理内存的 0 到 512MB。再然后上面都是空洞。关于布局的信息可以查阅Documentation/x86/x86_64/mm.txt
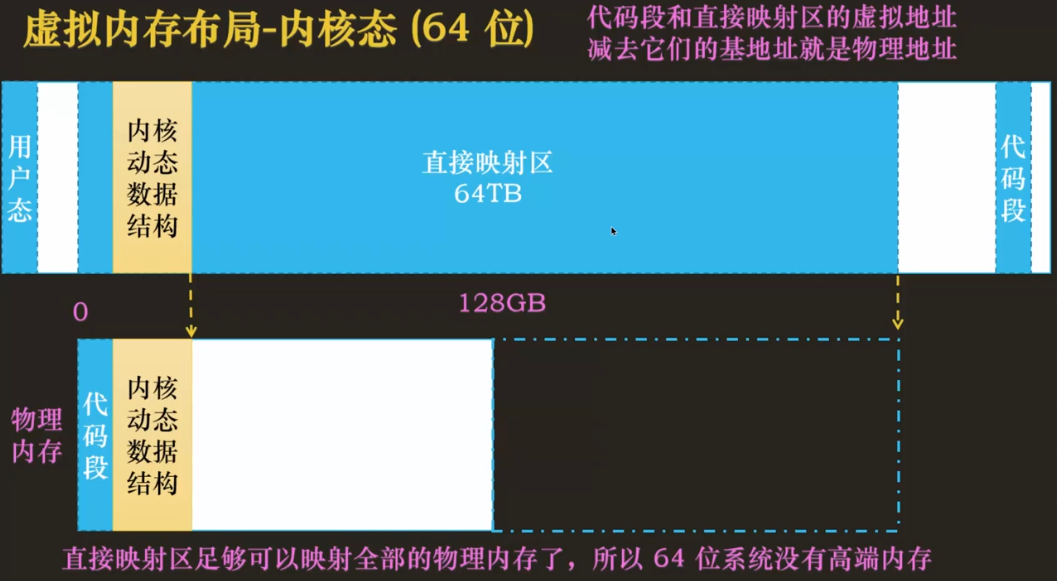
以下是物理内存的映射情况,可以看到内核态虚拟内存足够大,甚至有能力直接映射整个物理内存,所以说 64 位系统不需要高端内存。
物理内存模型
总共分为平坦、不连续、稀疏内存模型三种。
我们首先要知道如何去衡量 CPU 性能,显而易见的是响应一条指令的时间以及执行指令的吞吐量。如果我们要提高计算机的性能,从纵向看,我们能够提高单个 CPU 的主频,但是 CPU 的主频提高受到硬件制约,发展到如今,CPU 的主频已经非常高了,如果再提高,可能成本也会有大幅上升。从横向看,我们可以增加 CPU 的个数,这样可以并行执行指令,以提高吞吐量。
当一台计算机内有多个 CPU 时,该怎么去协调 CPU 访问内存呢?在一致内存访问 UMA(Uniform Memory Access)的方式下,多个 CPU 会与多个内存共享一条总线,CPU 将多个内存看成一个内存来使用,每个 CPU 访问主存是一样快的,但是由于是共享总线,需要检测总线是否忙碌,确定非忙碌后才让总线传输数据。这种系统完全受到总线带宽的限制。
为了改善 UMA,我们可以为每个 CPU 分配一块高速缓存,许多操作通过高速缓存就能完成,而不需要去访问数据总线,减少了总线流量,使得 UMA 能支持更多的 CPU。
如果 CPU 核数超过 100,那最好使用非一致内存访问 NUMA(Non-uniform Memory Access)架构的系统。在 NUMA 中,每个 CPU 都有自己独立的主存,每个 CPU 除了访问自己的主存,还能通过总线访问其它 CPU 的主存,当然,比起访问自己的主存,通过总线去访问其它 CPU 的主存肯定是要慢很多的。NUMA 将每个独立的主存抽象为 node,很显然,NUMA 有多个 node,而 UMA 架构下只有一个 node。
UMA 与 NUMA 都是对称多处理技术 SMP(Symmetrical Multi-Processing)的具体实现。
物理内存抽象
假设一个节点里物理内存有 4G,一个物理页 4K,页被抽象为一个结构体 page,用于管理对应的物理页(物理页和 page 实例不是一个东西,每个物理页 4k,但是每个 page 实例却不一定是 4k,得看结构体属性来决定)
1 | struct page{ |
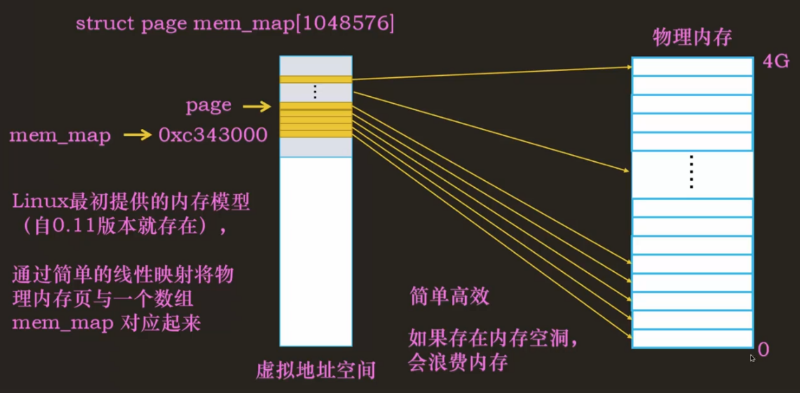
如果把物理内存看成一个 page 组成的数组,struct page mem_map[1048576],数组占用多大空间取决于每个 page 实例占用多大空间,而 page 实例所占空间则取决于 page 结构体中的属性的大小。
假设创建了一个 page 实例 p,并为它初始化,page 实例 p 存放在哪呢?
p 是一个指针,即一个虚拟地址,p 指向的虚拟地址是内核态虚拟地址空间(page 是内核为了管理物理内存抽象出来的数据结构,存放在内核态直接映射区),实例 p 存放在直接映射区映射到物理内存中的内核动态数据区域。
当用户态产生缺页异常要获取一个页时,应该怎么办?
最简单的一种方法就是在内核动态数据的 page 实例数组中遍历,直到找到满足条件的 page,返回(空闲的、大小合适的、连续的)。
那么怎么知道这个 page 是映射到哪个物理页号呢,是哪个物理页的抽象?
page 实例是直接映射的,计算 page 在 mem_map 的索引即可,物理页号=(page - mem_map) / 32,page 数组的索引就是页帧号,32 是 page 实例的大小。转换的函数是 page_to_pfn()。还提供了另一个方法,根据一个物理页号,找到某一个对应的 page 实例:pfn_to_page(): pfn*32 + mem_map,其中 32 是 page 实例的大小。
平坦内存模型
平坦内存模型 FLATMEM(flat memory model)是 Linux 最初提供的内存模型(自 0.11 版本就存在。它通过简单的线性映射将物理页与一个数组 mem_map 对应起来,简单而高效。但是如果存在内存空洞的话,会很浪费内存。)
什么是内存空洞?
实际上物理内存中有些地址用不了,比如 4G 内有一部分的地址是空洞无法访问的,称为不连续内存。平坦内存模型中的 mem_map 是数组,在内存中是连续的,即使对应物理内存的物理页部分是空洞的,也仍然要在 mem_map 中占一个位置。其实空洞这部分是不需要管理的,不需要 page 实例去映射。
NUMA 架构下就会出现内存空洞,它有多个节点组成,节点与节点之间的内存就有可能是不连续的。如果还是用平坦内存模型就很浪费。(当然,选用什么物理内存模型与硬件是什么架构没什么关系)
不连续内存模型
NUMA 架构下,每个节点之间的内存是有空洞的,但是每个节点内的内存是不存在空洞的。那么我们可以将每个节点的内存抽象为一个 mem_map,然后使用一个 mem_map_array 来存储每个 mem_map 的起始地址。效率没那么高,需要多次转换。但是如果内存之间有空洞,可以降低内存占用。这个模型与 NUMA 耦合太紧,只适用于 NUMA 架构下(如果 UMA 架构下内存出现大量空洞也用不了),NUMA 如果每个节点内的内存页出现大量空洞,也会出现浪费内存的情况。
因此不连续内存模型只是一个过渡用的中间产物,最终被稀疏内存模型替代。
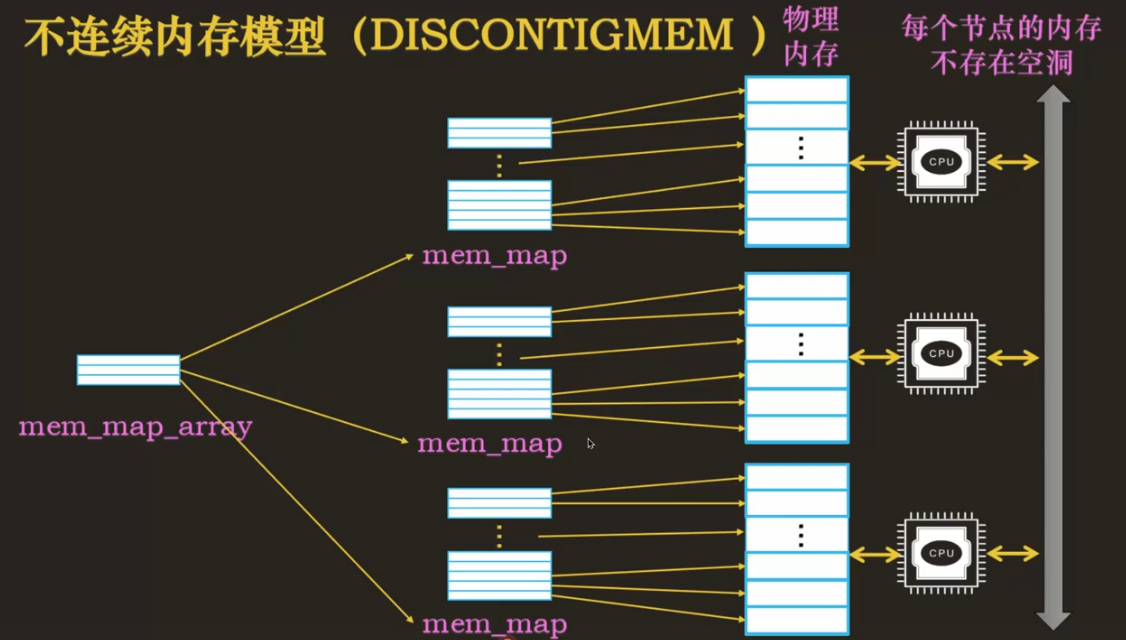
与平坦内存模型不同,不连续内存模型通过 page 实例获取物理页号要麻烦的多。
page_to_pfn():
- 从 page 的 flags 中拿到 nid(nid 是 node id,节点号。flags 值在系统初始化时设置)
- 根据 nid 拿到 node 以及对应 mem_map
- (page - node.mem_map) / 32 + node.start_pfn(先获取到 page 在 mem_map 中的索引,然后加上初始页号即可。node.start_pfn 是每个节点的起始页号,在初始化时设置)
通过pfn_to_page()可以通过物理页号得到 page 实例
pfn_to_page():
- 根据 pfn 拿到 nid(哈希表)
- 根据 nid 拿到 node 以及对应的 mem_map
- node.mem_map + pfn - node.start_pfn
稀疏内存模型
稀疏内存模型将物理内存分为多个段(mem_section,多个 mem_section 存储在 mem_section_map 中),每个段内有多个 page 实例,假设每个段大小为 2^27 = 128MB。其实感觉和多级分页的设计差不多,如果对应上的段是空洞,则段指向 None 即可,节省空间。有可插拔的特性,与 NUMA 架构高度解耦。
一个 mem_section_map 的数组需要存储在一个页帧中,大小为SECTIONS_PER_ROOT=(PAGE_SIZE / sizeof(struct mem_section))。
根据 page 实例来计算页号看起来复杂,其实只是计算下标后在二维数组中查找而已,实现起来也另有技巧。
page_to_pfn():
- 从 page 的 flags 获取全局段号 nr(每个段都有个段号标识)。
- 计算 page 实例所属的 mem_section 的基地址:
假设 SECTIONS_PER_ROOT=3(mem_section_map 中有三个元素),根据段号 nr 和 SECTION_PER_ROOT 获取到 mem_section_map 在 ROOTS 中的索引。然后使用 nr & SECTIONS_PER_ROOT 得到段在 mem_section_map 的索引。 - 获取到 mem_map(即 mem_sections 的基地址)。使用 page - mem_map + start_pfn(每个段都有自己的 start_pfn)。
pfn_to_page():
- 计算 pfn 的全局段号 nr,pfn >> PFN_SECTION_SHIFT(定义好的,27-12)
pfn * 4KB / 128MB = pfn / (2^(27-12)) - 计算 page 所属的 mem_map
mem_map = ROOTS[nr / SECTIONS_PER_ROOT][nr & SECTIONS_PER_ROOT] - mem_map + (pfn - start_pfn)

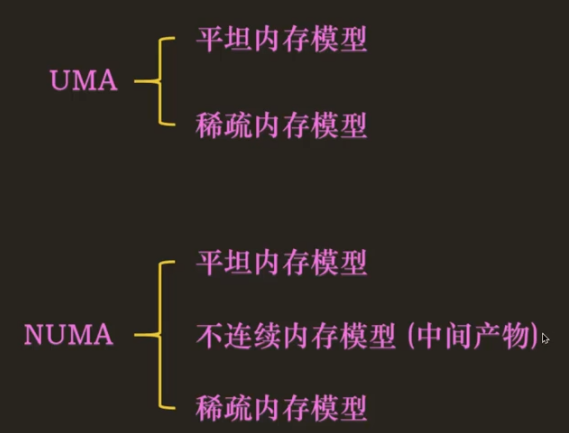
三种内存模型的关系
如图,UMA 架构一般会选用平坦内存模型以及稀疏内存模型,因为它将主存看做一块。NUMA 架构则三种内存模型都可以使用。
总结
本文从虚拟内存入手,介绍了 32 位、64 位系统下的内核态和用户态虚拟内存布局,其中 32 位内核态由于空间太小,需要通过固定映射、临时映射来使得有限的内核态虚拟地址空间去访问更多的物理内存中的高端内存,而 64 位系统下由于空间充足,就显得很豪气,即使是通过直接映射也能轻易映射所有的物理内存,毕竟 128TB 的物理内存对于当下一台计算机而言还是极其少见的。接着,我们又着眼于物理页,简要介绍了两种 CPU 与内存交互的架构和三种物理内存模型。实际上,三种内存模型的实现远比本文所讲的复杂的多,有兴趣者可以自己深入学习一下(推荐阅读)。








