一文了解 OS-内存管理
内存对齐
为了程序可以在所有处理器下运行,以此提升性能
很多处理器每次只能从内存中取出特定字节的数据,如 1 次访存只能取出 4 个字节数据,那么该处理器访问的地址必须是 4 的倍数,如 0x0, 0x4 等
对于 amd64 与 x86 处理器是不需要考虑内存对其的事情,他们的处理器经过特殊处理,可以读取任意小的变量
- 如果不进行内存对齐
一个变量的值可能要跨两个内存块,需要两次访存才能获取,损耗 cpu 性能
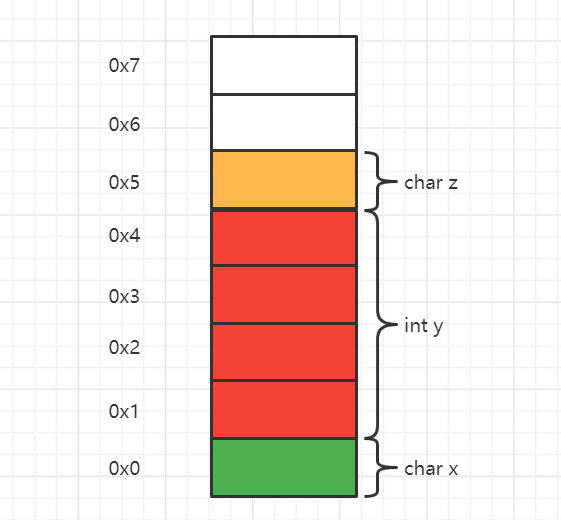
如上图,该处理器一次访存能取 4 字节数据。当其需要取 int 变量 y 时,需要两次读取 0x0,0x4.将不需要的数据舍弃,将 0x1-0x4 拼接得到变量 y。降低运行性能
空闲链表
空闲块结构:头部 + 有效载荷 + 填充 + 脚部
其中,头部、填充、脚部三部分的内存,是在分配内存的同时就分配给内存块了,并不是独立出来

空闲链表概念:将空闲内存块串成一个链表方便管理
由于空闲内存块大小不一,如果串成一个链表,分配时需要遍历整个链表,效率较低。因此操作系统会按照空闲内存块大小区分出多个空闲链表
将每个空闲链表的表头存放在数组中
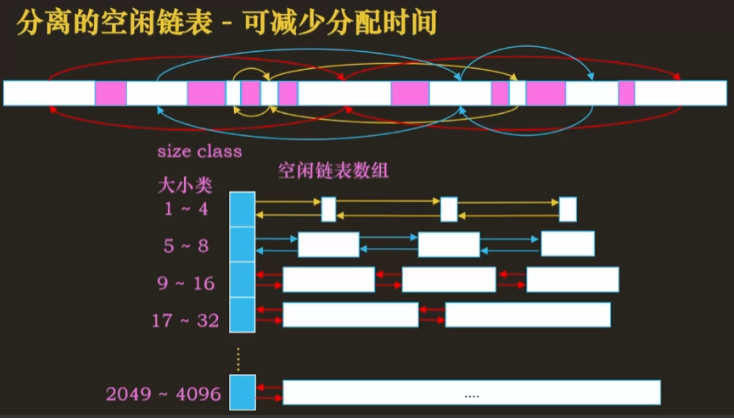
- 当出现内存释放时,可以使用头插法或者地址维护法来归还内存
- 头插法:直接将空闲内存块插入空闲链表头部(速度快,但没考虑空闲块合并,会造成内存碎片越来越多)
- 地址维护法:根据空闲内存块的地址大小来顺序维护(速度快,合并内存块速度快,内存使用率高)
- 地址维护 + 首次适配
用户态虚拟内存分配
概念
用户态主要需要分配的是堆内存
操作系统将堆分为多个空闲块来管理

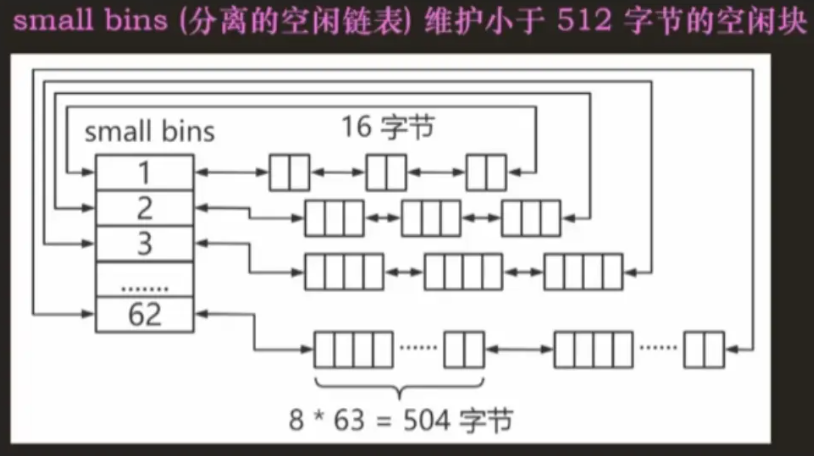
Small bins:主要维护小于 512 字节的空闲内存块
- 当 unsorted bin 被扫描时,会将满足条件的内存块加入这里
- 当释放了空闲块之后,会检索相邻的空闲块,可以合并的话就进行合并,并将合并之后的空闲块加入到 unsorted bin 中
Large bins:主要维护大于等于 512 字节的空闲内存块
Top chunk:堆顶的内存块
Unsorted bin:在 large bins 中分割出的空闲块会先放在这里
存储需要移动位置的空闲块,等待合适的时机再进行移动
当 large bins 中分割出的新的空闲块或者small、large bins 合并出新的空闲块,加入这里

当需要分配内存块时,如果 fast bins、small bins 都不满足要求,则会将 fast bins 中所有的空闲块合并之后,加入这里,并扫描 unsorted bins 中有无满足条件的空闲块,有则返回,没有,则将当前扫描到的内存块加入合适的 bin 中
这里的内存块并不会直接进行合并
Fast bins:为了快速进行内存块分配存在的特殊区域
为了满足很小的内存需求(小于 80 字节)
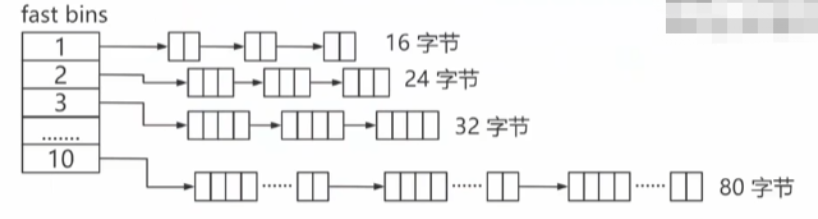
当释放了很小的内存块时,优先存储在这里
每个 bins 都会分成多个空闲链表,方便管理
内存分配流程
- 先扫描 fast bins
有符合大小的就直接返回
没有的话去搜索 small bins
- 搜索 small bins
有符合大小的就直接返回
没有的话,尝试合并 fast bins 中的空闲内存块,合并后加入 unsorted bin 中。搜索 unsorted bin
- 搜索 unsorted bin
优先检查 last remainder,满足条件则分割返回,分割剩下的加入 unsorted bin 中,否则继续扫描
当前扫描的空闲块不满足条件,则将其加入对应的 small bins、large bins 中,往后继续扫描
- 找到满足的空闲块,返回,否则继续扫描
- 扫描次数过多(1w 次)或 unsorted bin 都扫描完了还未找到满足条件的空闲块,则去搜索 large bins
- 搜索 large bins
找到需要的空闲块,分割,返回。剩下的作为 last remainder 加入 unsorted bin,没有则继续搜索
没有则查找 top chunk
- 查找 top chunk
Top chunk 满足要求,分割 top chunk,返回
不满足要求,则合并 fast bins,从头开始搜索
堆内存不够用时,发起系统调用,希望操作系统能分配更多的堆内存
- 系统调用
需求内存小于 128KB,通过 sbrk 函数申请
需求内存大于等于 128KB,通过 mmap 申请内存
内存释放流程
- 检查 mmap
检查是否是 mmap 获取的内存,是的话使用 munmap 删除内存映射,直接返回
否则检查内存块大小
- 检查内存块大小
如果属于 fast bins(小于 80B),就返回
不是则合并前一个内存块,并检查后一个内存块是否是 top chunk
- 检查是否是 top chunk
是,合并到 top chunk
否则检查后一个内存块是否空闲
- 检查后一个内存块
空闲,合并,插入 unsorted bin 中
不空闲,将当前内存块插入 unsorted bin
物理内存分配
并不存在内核态的虚拟内存分配机制。
伙伴系统解决了物理内存分配的外部碎片问题
- 对于内核态的内存来说,操作系统会直接分配给其物理内存
无论是用户态虚拟内存需要物理内存,还是内核态需要物理内存,都需要通过伙伴系统来获取空闲的物理内存
物理内存的分配单位是页(4KB),并通过伙伴系统对所有物理页进行管理和分配
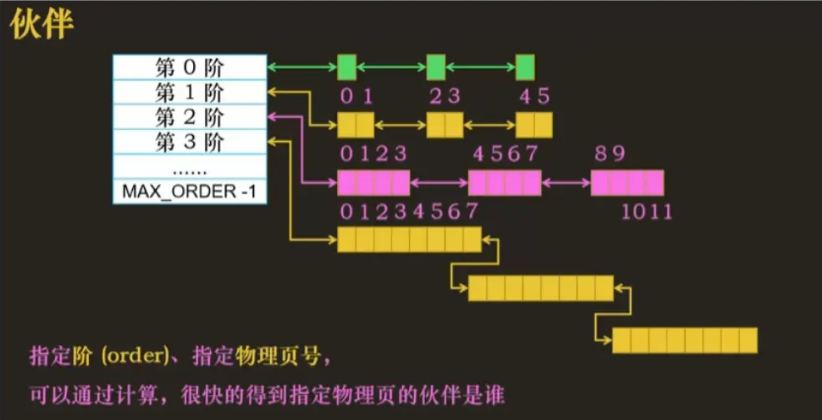
如上图,伙伴系统将大小不同的空闲内存块按照阶数来划分,第 n 个阶数对应的物理块大小为 2^n 个物理页
伙伴
- 一个物理块和它后边地址和大小相同的物理块是伙伴
- 第一阶中 0,1 是伙伴,第二阶中 01,23 是伙伴
基于伙伴系统的内存分配流程
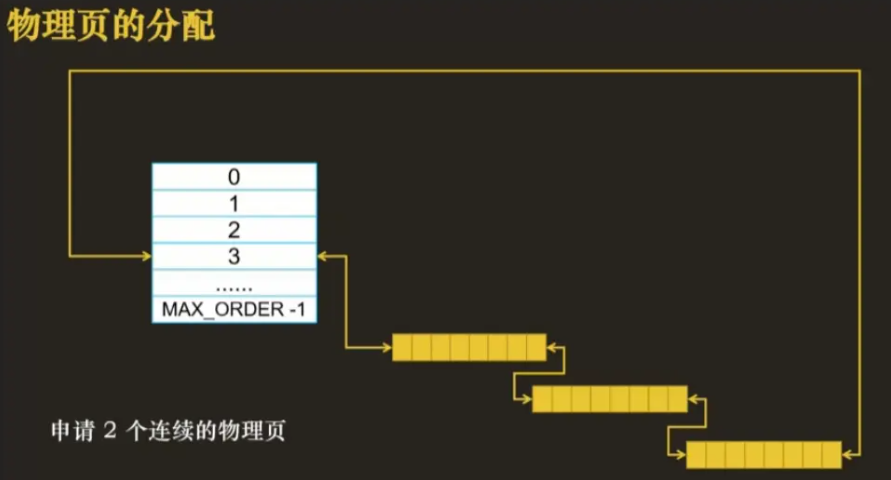
假设需要申请 2 个连续的物理页,此时第 1 阶和第 2 阶都没有满足条件的物理页,因此去第三阶找
- 3 阶的大小是 2^3 即 8 个物理页,返回需要的俩,剩余 6 个要放回空闲链表中
将 3 阶 8 个物理页一分为二,即一半是 4 个物理页,将一半插入 2 阶空闲链表的表头
- 将剩下的一半的一半即 2 个物理页插入到 1 阶的表头
- 将剩余的 2 个物理页返回
整个分割的过程中,可以通过伙伴的编号一直查找另一半,这也是伙伴系统高效的原因
基于伙伴系统的内存释放流程
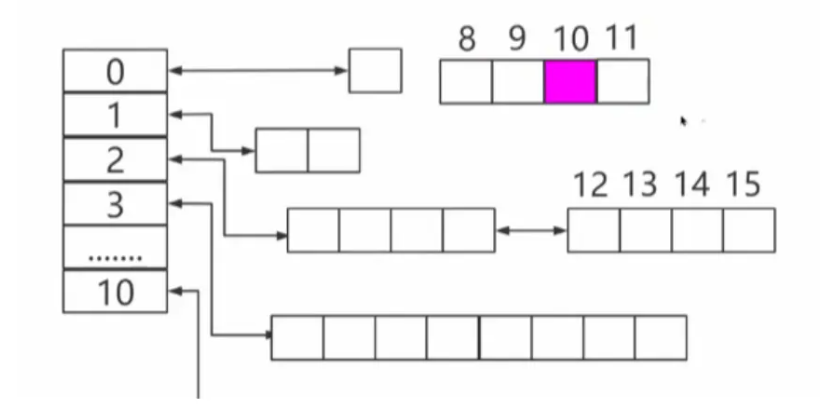
释放一个编号为 10 的物理页
理论上是应该将该物理页放在第 1 阶,但是由于有空闲的 11(10 的伙伴),就将俩合并,作为 10 11 插入第二阶
之后不断递归完成插入流程
slab 分配器
本篇暂未涉及 slab 着色
概念
功能:为内核程序分配小对象内存。 即从伙伴系统获取物理页后,如果直接分配给内核程序,会造成较大的内存碎片,因此 slab 将其分割为多个小块
减少伙伴系统导致的外部内存碎片,提供小内存。
维护常用对象的缓存。对于内核中使用的许多结构,初始化对象所需的时间可等于或超过为其分配空间的成本。当创建一个新的 slab 时,许多对象将被打包到其中并使用构造函数(如果有)进行初始化。释放对象后,它会保持其初始化状态,这样可以快速分配对象
提高 CPU 硬件缓存的利用率
由于空闲链表的最大缺点是缺少全局控制。当可用内存紧缺时,操作系统无法通知到每个空闲链表,让它们收缩自己的缓存空间以释放一些内存,操作系统甚至不知道空闲链表的存在。slab 层即为了弥补此缺陷而存在
切分方式:
通用:固定大小的小块,如 8 字节、16 字节等
专用:固定对象的小块,如 vma(vm_area_struct),216 字节
概念:
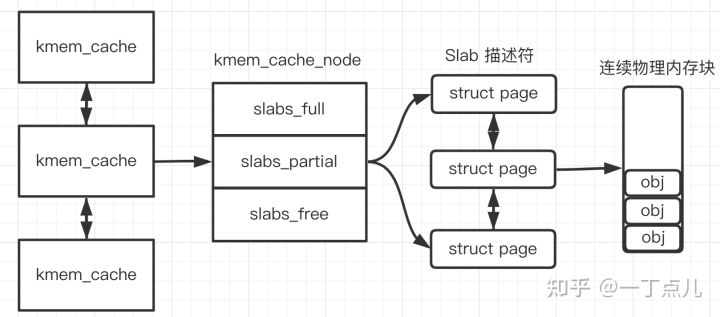
slab 是一个数据结构,一个 slab 中存储多个物理页,即从伙伴系统中一次性分配到的物理页共同组成一个 slab
根据切分方式和分为两种 slab
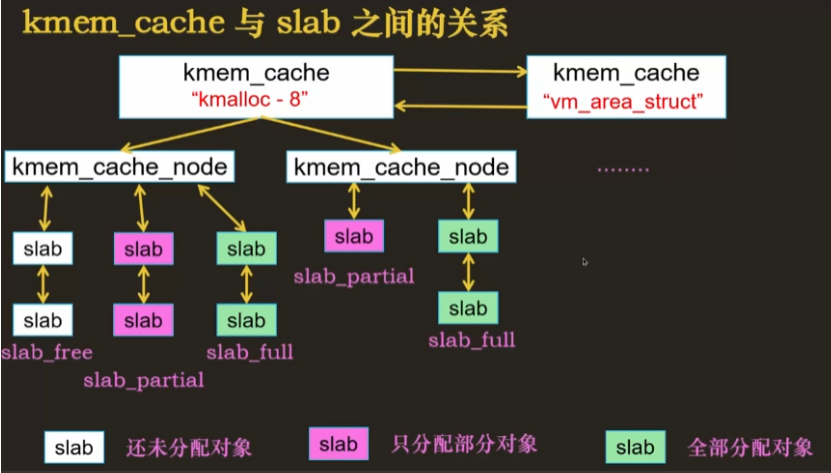
- 通用 slab:内部存储不同的对象,只要对象大小不超过 slab 元素大小即可
- 专用 slab:内部存储单一种对象,专门用于分配常用对象的内存
- 由于通用 slab 会造成内存浪费,因此才有专用 slab,提高内存利用率
slab 将对象切分好后存入一个数组管理

管理 slab
由于同一种对象的会有多个,需要多个 slab 来存储该对象
- 使用 kmem_cache 管理多个 slab
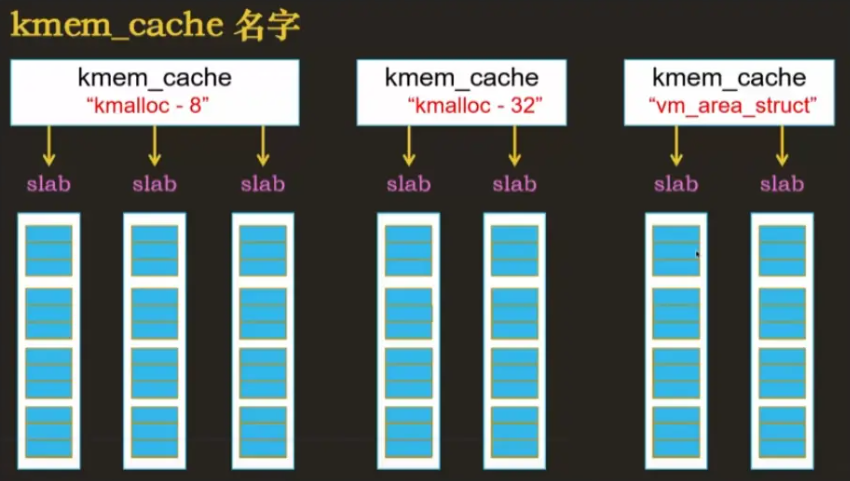
将同一对象的 slab 归到一个 kmem_cache 下
kmem_cache 的种类
- kmalloc-8,kmalloc-32 为通用缓存,大小为 8 字节和 32 字节
- vm_area_struct 为专用缓存,大小为专用对象的大小
kmem_cache 作为 cache 的意义
- 当内核态申请物理内存时,需要通过伙伴系统获取内存。释放内存时直接返还给操作系统,下次申请时还是需要通过伙伴系统获取内存,这个过程有点多余
- 因此直接将需要分配和释放的对象存储在 slab 中,下次需要时再直接从 slab 中分配,节省了分配和释放物理页的操作流程
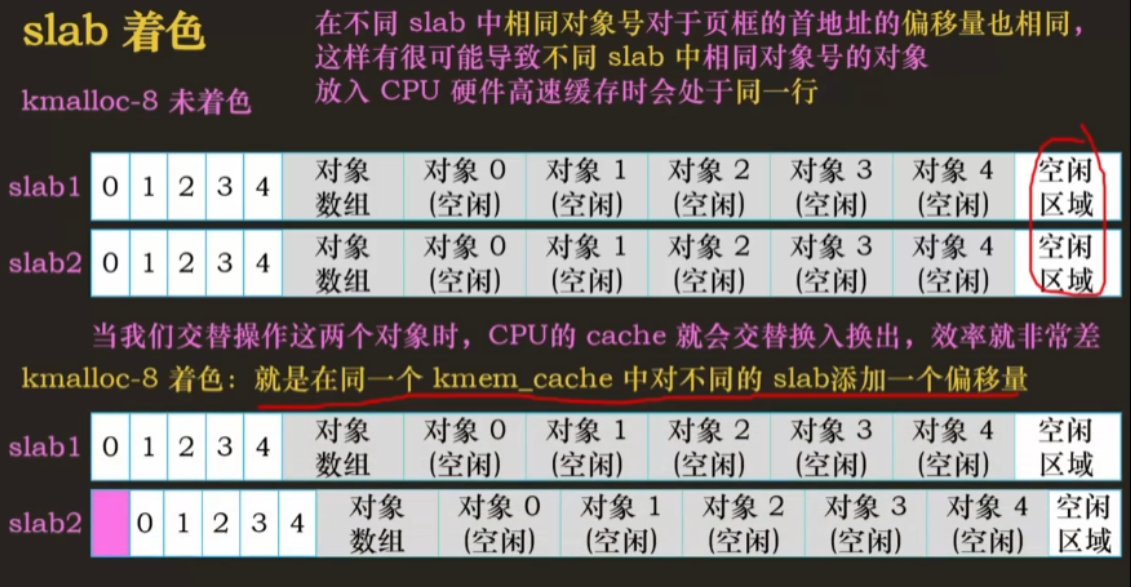
slab 着色
如果将对象包装到 slab 中后仍有剩余空间,则将剩余空间用于为 SLAB 着色
slab 着色是一种尝试使不同 slab 中的对象使用 CPU 硬件缓存中不同行的方案。通过将对象放置在 slab 中的不同起始偏移处,对象可能会在 CPU 缓存中使用不同的行,从而有助于确保来自同一 slab 缓存的对象不太可能相互刷新。通过这种方案,原本被浪费掉的空间可以实现一项新功能。
在不同的 slab 中,可能出现两个对象在高速缓存中映射到同一个缓存组的问题
- 容易导致同一缓存组满了,需要进行缓存替换
- 如果交替操作俩对象,cpu 的 cache 要频繁换入换出,效率低
解决:将空闲区域的一部分填充到 slab 最头部,保证标志位和组号不同
NUMA 架构下的 kmem_cache
kmem_cache 内部结构
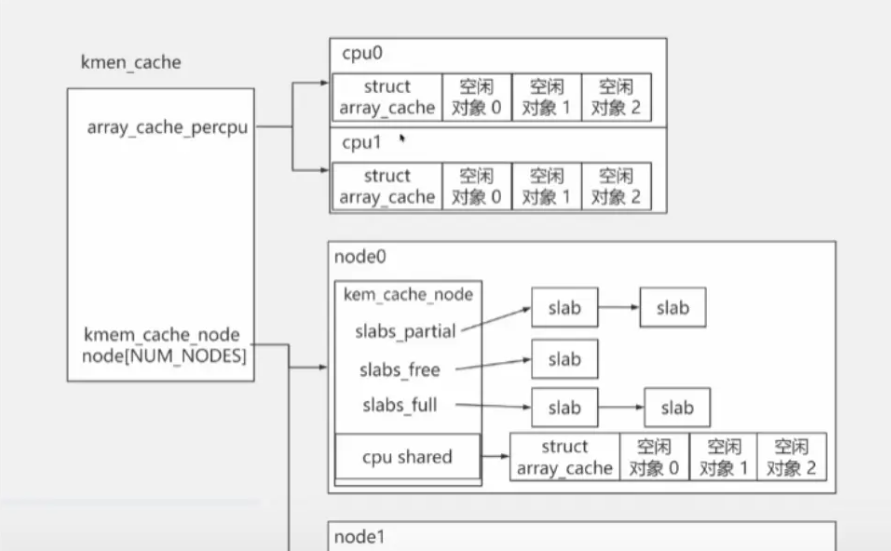
在 NUMA 架构下有很多个 node,针对某个 node,其 kmem_cache 又称为 kmem_cache_node。
每个 kmem_cache 都有两部分
一部分是kmem_cache_node(一个数组),存放了该 node 切分成所有相同大小的 slab,其中 slab 分为未分配、部分分配、全分配三类,还有个 cpu_shared,指该数组中的空闲对象,是共享的
- 初始化时是没有 slab 的。kmem_cache 中的slab 数量是动态变化的,当 slab 数量太多时,kmem_cache 会将一些 slab 释放回伙伴系统中
另一部分就是上述的array_cache_precpu(cpu 高速缓存),存储每个 cpu 的空闲对象的缓存
- 提高硬件缓存的命中率:每个 CPU 都有它们自己的硬件高速缓存(在多核 CPU 下,通常 L1/L2 为 CPU 单独占有,L2/L3 为所有 CPU 核共享的)。当此 CPU 上释放对象时,又再次申请一个相同大小的对象时,原对象很可能还在这个 CPU 的硬件高速缓存中。内核为每个 CPU 维护一个这样的链表,当需要新的对象时,会优先尝试从当前 CPU 的本地 CPU 空闲对象链表获取相应大小的对象,这样就能更快地分配对象。
- 大大减少缓存失效
- precpu 接口缓存 - 对齐所有数据,确保在访问同一处理器的数据时不会将另一个处理器数据带入同一个缓存线上
- 减少锁的竞争:假设多个 CPU 同时申请一个大小的 slab,这时候如果没有本地 CPU 空闲对象链表,就会导致分配流程是互斥的,需要上锁,就导致分配效率低。
- 此处的空闲对象缓存是不共享的,该 cpu 需要内存时优先在此分配
- 提高硬件缓存的命中率:每个 CPU 都有它们自己的硬件高速缓存(在多核 CPU 下,通常 L1/L2 为 CPU 单独占有,L2/L3 为所有 CPU 核共享的)。当此 CPU 上释放对象时,又再次申请一个相同大小的对象时,原对象很可能还在这个 CPU 的硬件高速缓存中。内核为每个 CPU 维护一个这样的链表,当需要新的对象时,会优先尝试从当前 CPU 的本地 CPU 空闲对象链表获取相应大小的对象,这样就能更快地分配对象。
内核态下申请内存的流程
根据申请对象的方法(kmalloc,kmem_cache_alloc)来判断是申请通用对象还是申请专用对象
- 根据通用对象大小或专用对象名字找到对应的 kmem_cache
查找 cpu 高速缓存中(array_cache_precpu),该 cpu 是否有空闲对象
- 有则从中获取
- 没有则去 kmem_cache_node 中查找
查看 cpu 共享缓存中是否有空闲对象(所有 node 的共享)
- 有则从 cpu 共享缓存中分配并返回,将一部分共享的空闲对象放到该 cpu 的私有缓存中
- 没有则从当前 node 的 slab 里找
- 如果还没有,则去伙伴系统中申请,存到 slab_free 中,并放一部分空闲对象到该 cpu 对应 node 的共享缓存中
- 综述
- 找到对应的 kmem_cache
- 去cpu 私有缓存中查找(array_cache_precpu)
- 去cpu 共享缓存中找(所有 node 的 cpu_shared)
- 去该 cpu 对应node 的 slab 中获取
- slab 中也没有则从伙伴系统中申请物理页,切分。一部分放到该 cpu 的 node 的 slab_free 中,一部分放到该 cpu 的 node 的共享缓存中
内核态下释放内存的流程
获取被释放的对象
将该对象放入 cpu 高速缓存
如果私有缓存太多,则放入该 cpu 对应 node 的共享缓存中
如果 cpu 对应 node 的共享缓存太多,放入对应 node 的 slab 中
如果 slab_free 太多,将 slab 对应页返回给操作系统
申请非连续物理内存
通过伙伴系统+kmalloc申请的都是连续的物理页,会造成一定的外部的内存碎片
- 如果想要节省内存,要去申请非连续的物理内存,使用 vmalloc 方法
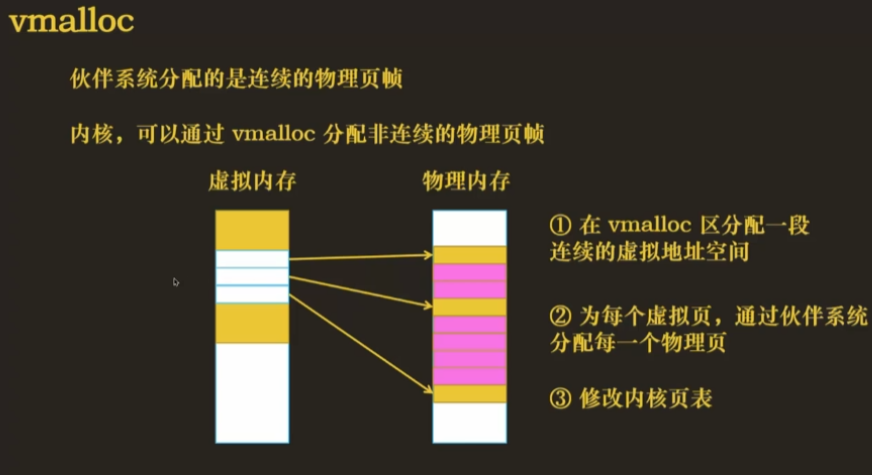
由于 vmalloc 区不在直接映射区,虚拟地址与物理地址不能够直接转换,因此需要修改内核页表(程序页表里的映射关系也要修改)
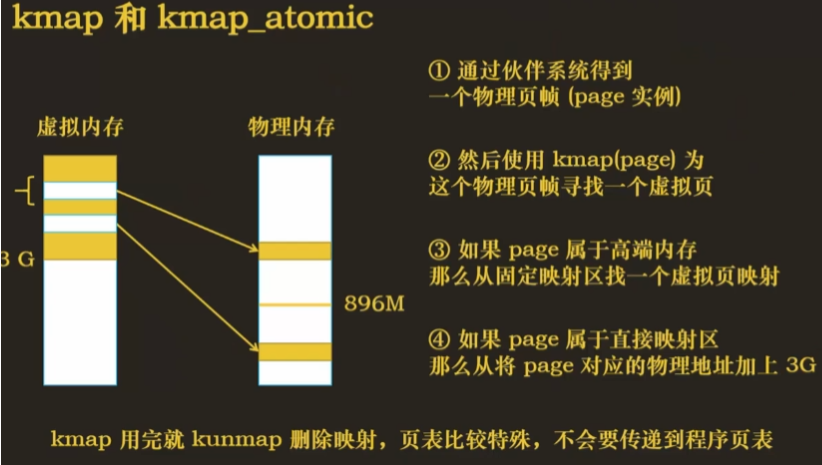
- 使用 kmap 与 kmap_atomic 也可以
- kmap 会通过伙伴系统获取物理页
- 如果该物理页是高端内存,则为该物理页在持久映射区找到一个虚拟页
- 如果在直接映射区,直接映射即可
- kmap 使用完后使用 kunmap 删除映射
- 其中 kmap 申请的物理页和虚拟页的映射关系不会传递到程序页表中(程序无法通过页表直接获取)
- kmap 会通过伙伴系统获取物理页
内存分配方法总结
用户态申请内存
- mmap
- 通过 mmap直接在mmap 内存映射区申请一定大小的虚拟内存,之后由缺页异常 + 伙伴系统获得物理内存
- 通过 munmap 释放
- 一文了解 OS-内存映射
- malloc
- 通过搜索空闲链表和 bins,找到合适的虚拟内存进行分配,之后通过缺页异常 + 伙伴系统来获取物理内存
- 通过 free 释放内存,放回到空闲链表+bins 中
- 当申请内存<128KB 时,malloc 实际调用 sbrk 申请内存
- 当申请内存>=128KB 时,实际调用 mmap 申请内存
- mmap
内核态申请内存
- kmalloc
- 先通过伙伴系统找到物理页,再根据高速缓存+slab 分配器,从高速缓存+kmem_cache 中找到通用的空闲对象
- 也可以直接通过 kamlloc 申请多个连续物理页直接使用
- 通过 free 释放,释放后内存放回高速缓存+kmem_cache 中
- kmem_cache_alloc
- 想通过伙伴系统找到物理页,再根据kmem_cache(高速缓存+cpu_shared+slab 分配器)获取专用的空闲对象
- 通过 free 释放,释放后内存放回高速缓存+kmem_cache 中
- vmalloc
- 通过伙伴系统找到物理页,在 vmalloc 区建立映射,并修改内核页表
- 只有在不得已的情况下才会使用(为了获得大块内存时),调用 vmalloc() 必须要建立页表项,获得的页必须一个一个进行映射(物理上不连续),导致比直接内存映射大得多的 TLB 抖动。
- kmap
- 通过伙伴系统找到物理页,寻找虚拟也建立映射,不用改内核页表
- kunmap 删除映射
- kmalloc
参考
抖码课堂
Linux 内存管理之 slab 1:slab 原理(+buddy 伙伴系统)








