一文了解 WebSocket 协议
为什么需要 WebSocket
短轮训->长轮训->基于流->WebSocket
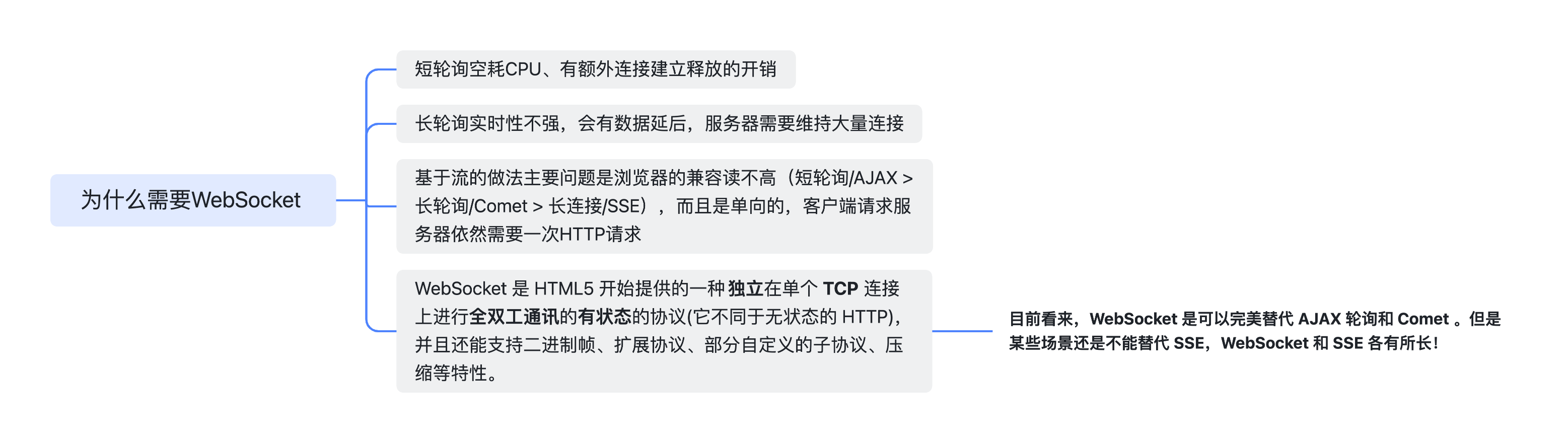
TCP 长连接就是 WebSocket 的基础,但是如果是 HTTP 的长连接,本质上还是 Request/Response 消息对,仍然会造成资源的浪费、实时性不强等问题
特点
-
建立在 TCP 之上
-
与 HTTP 有良好兼容性
-
没有同源限制,客户端可以与任意服务器通信
-
标识符是ws/wss,服务器地址是URL
-
可以发送文本和二进制数据
-
数据格式轻量,性能开销小,通信高效。连接创建后,ws 客户端、服务端进行数据交换时,协议控制的数据包头部较小。在不包含头部的情况下,服务端到客户端的包头只有 2~10 字节(取决于数据包长度),客户端到服务端的的话,需要加上额外的 4 字节的掩码。而 HTTP 协议每次通信都需要携带完整的头部;
建立连接
WebSocket 的目的是取代 HTTP 在双向通信的场景下使用,所以有些实现方式也是基于 HTTP 的(比如默认端口为 80/443),有向下兼容的意思。
客户端发起协议升级
1 | GET / |
服务端响应协议升级
101 表示服务器收到了客户端切换协议的请求,并且同意切换到此协议。
1 | 101 Switching Protocols |
服务端回应的 HTTP 状态码只能在握手阶段使用。过了握手阶段后,就只能采用特定的错误码。
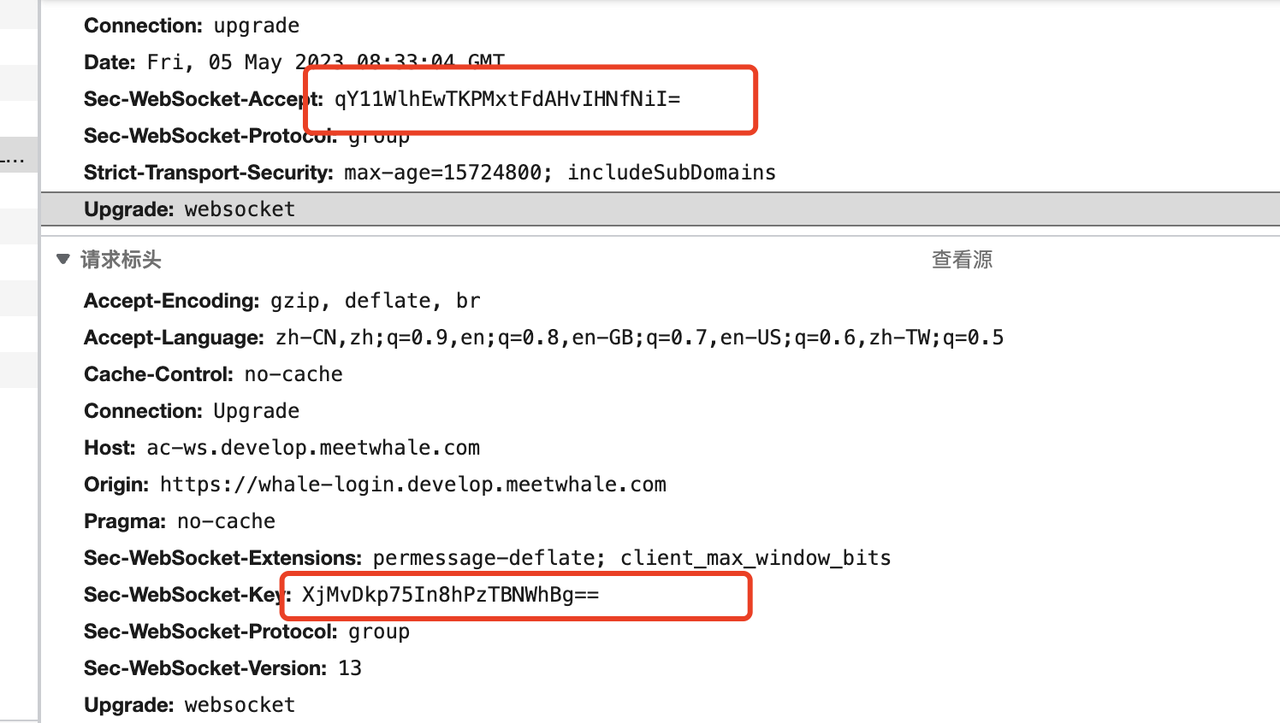
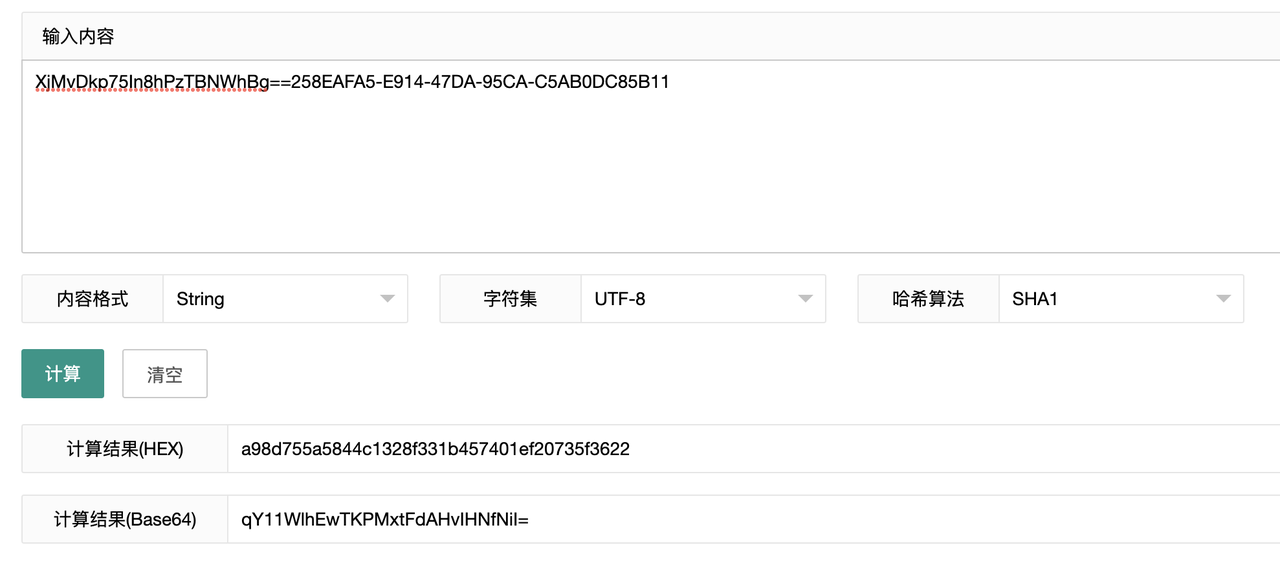
Sec-WebSocket-Accept 计算
根据客户端请求首部的 Sec-WebSocket-Key 进行计算。
-
将 Sec-WebSocket-Key 跟 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 拼接
-
通过 SHA1 计算出摘要,并转成 base64 字符串
toBase64( sha1( Sec-WebSocket-Key + 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 ) )
Sec-WebSocket-Key/Accept 作用
主要用于提供基础防护,减少恶意连接和意外连接
-
为了避免服务端收到非法 websocket 连接(如 http 客户端不小心请求 websocket 服务)。
-
确保服务端能理解 websocket 连接,客户端能通过 Sec-WebSocket-Key 来确保认识 ws 协议(服务端不仅需要处理 Sec-WebSocket-Key,还需要实现 ws 协议,否则没有意义)。
-
在浏览器中发起 ajax 请求,设置 Header 时,Sec-WebSocket-Key 以及其他相关 header 是被禁止的,防止 ajax 请求意外请求升级升级。
- 以“Sec-”开头的 Header 可以避免被浏览器脚本读取到,这样攻击者就不能利用 XMLHttpRequest 伪造 WebSocket 请求来执行跨协议攻击,因为 XMLHttpRequest 接口不允许设置 Sec-开头的 Header。
-
可以防止反向代理返回错误的数据。
-
Sec-WebSocket-Key 主要目的不是为了确保数据安全性,因为转换公式时公开的,主要预防一些常见的非故意意外情况。
只能带来基本保证,无法确保连接安全、数据安全、客户端/服务端是否合法。
Sec-WebSocket-Protocol 子协议
详情见:WebSocket API: Sec-WebSocket-Protocol (Subprotocol) header support
在笔者初识子协议时,曾用其作为 Token 的存放位置 qwq,因为 WebSocket 无法自定义请求头。实际生产场景中,可以通过 SubProtocol 区分不同的应用场景。比如笔者的应用场景有推送、协同两种,就能自定义 SubProtocol 去区分。
数据帧格式
通信的最小单位是帧 frame,由一个或多个帧组合为一条完整的消息 message
-
发送:将消息切割为多个帧,并发送给服务端
-
接收:组成一个完整消息
详细定义:RFC ft-ietf-hybi-thewebsocketprotocol: The WebSocket Protocol
数据帧统一格式:
1 | 0 1 2 3 |
- FIN 1bit
如果为 1,表示这是该消息的最后一个分片。否则为 0
- RSV1, RSV2, RSV3 3bit
一般情况下为全 0,用于客户端与服务端协商采用 WebSocket 扩展,值由扩展进行定义,如果出现非 0 值且没有使用扩展,则连接出错
- Opcode 4bit
操作代码,决定该如何解析后续 payload。如果操作代码未知,则接收端应断开连接。可选如下
1 | x0:表示一个延续帧。当Opcode为0时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。 |
- Mask 1bit
表示是否要对 data payload 进行掩码操作。从客户端发向服务端要,从服务端发向客户端不用。当服务端接收到未进行掩码操作的数据,服务端应该断开连接
Mask 为 1,Masking-key 中应该定义一个掩码键 masking key,并用其对 data payload 进行反掩码。所有客户端发到服务端的帧,mask 都为 1
- Payload length 7bit
data payload 的长度,单位为字节。如果 patload length == x
1 | x为0~126:数据的长度为x字节。 |
payload length 下面有扩展的长度。如果他超过 1 个字节,payload length 的二进制表达采用网络序(big endian,重要的位在前)
- Masking-key 32bit
Data playload length 不包含 masking-key
- Playload data x+y bytes
包含扩展数据和应用数据,其中扩展数据 x 字节,应用数据 y 字节
扩展数据:不协商使用就为 0。所有扩展数据都要声明扩展数据的长度,或者声明如何能计算出扩展数据长度。都在握手阶段协商好,如果扩展数据存在,那么 data payload length 就包含扩展数据长度
应用数据:任意的应用数据,在扩展数据之后。data payload length - 扩展数据长度即为应用数据长度
掩码算法
Masking-key 是客户端挑出的 32bit 随机数。
掩码和反掩码操作都用如下算法
定义:
1 | original-octet-i:为原始数据的第i字节; |
original-octet-i与masking-key-octet-j异或后得到transformed-octet-i
1 | j = i mod 4 |
掩码操作不会影响数据载荷的长度。
数据掩码作用
主要作用是增强协议安全性,但不是为了保护数据本身,因为算法本身就是公开的,且不复杂。实际作用是为了防止早期版本的协议中存在的代理缓存污染攻击(proxy cache poisoning attacks)等问题。
详细如下:Talking to Yourself for Fun and Profit
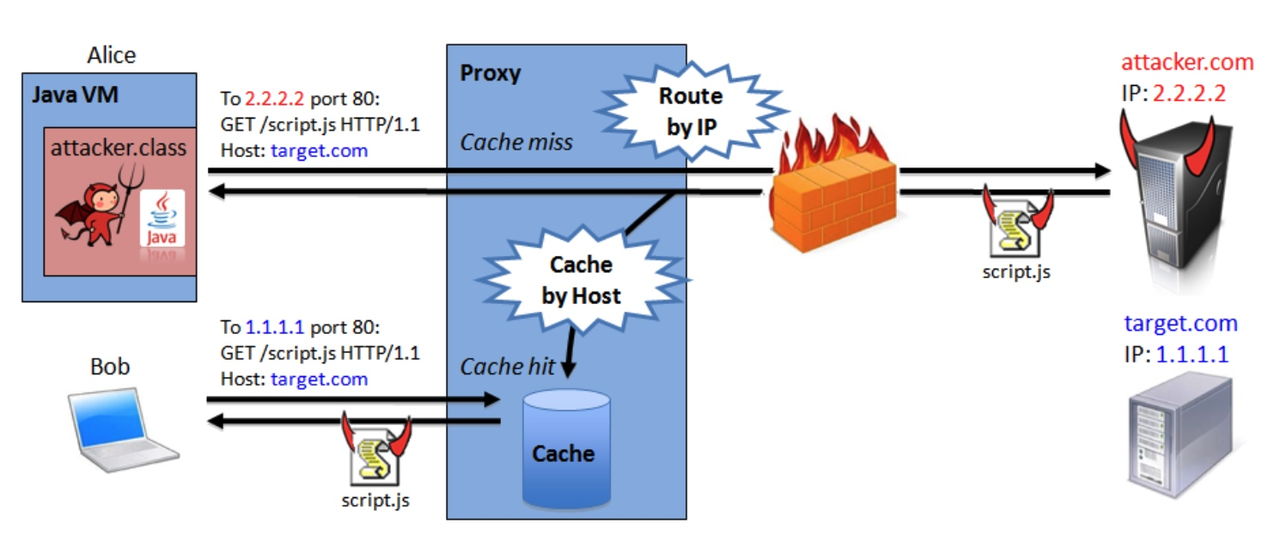
整个攻击过程分为两步:
攻击步骤一:
-
攻击者浏览器 向 邪恶服务器 发起 WebSocket 连接。根据前文,首先是一个协议升级请求。
-
协议升级请求 实际到达 代理服务器。
-
代理服务器 将协议升级请求转发到 邪恶服务器。
-
邪恶服务器 同意连接,代理服务器 将响应转发给 攻击者。
由于 upgrade 的实现上有缺陷,代理服务器 以为之前转发的是普通的 HTTP 消息。因此,当 邪恶服务器 同意连接,代理服务器 以为本次会话已经结束。
攻击步骤二:
-
攻击者 在之前建立的连接上,通过 WebSocket 的接口向 邪恶服务器 发送数据,且数据是精心构造的 HTTP 格式的文本。其中包含了 正义资源 的地址,以及一个伪造的 Host(指向 正义服务器)。
-
请求到达 代理服务器。虽然复用了之前的 TCP 连接,但 代理服务器 以为是新的 HTTP 请求。
-
代理服务器 向 邪恶服务器 请求 邪恶资源(script.js)。
-
邪恶服务器 返回 邪恶资源。代理服务器 缓存住 邪恶资源(url 是对的,且 Host 是 正义服务器 的地址)。
到这里,受害者可以登场了:
-
受害者 通过 代理服务器 访问 正义服务器 的 正义资源。
-
代理服务器 检查该资源的 url、host,发现本地有一份缓存(伪造的)。
-
代理服务器 将 邪恶资源 返回给 受害者。
-
受害者 卒。
整个过程最大的 Bug 点是“在 upgrade 协议实现上有缺陷的代理服务器(错把 Websocket 当做是普通的 HTTP 消息)”,而数据掩码也就是为了针对这类“愚蠢”的代理服务器。因为数据掩码在每次消息传输中都由客户端随机生成,经过掩码算法后,明文消息变成了不被识别的字节,代理服务器发现每次传来的消息都不同,那它只好选择通过,而不是做缓存处理。
如果没有这个掩码限制,攻击者只需要在网上放个钓鱼网站骗人去访问,就可以在短时间内展开大范围攻击。安全的范围很大,防止代理缓存污染攻击也算在安全范畴内,所以不要局限于一点,这样容易进死胡同。
数据传输
连接建立后,后续操作都是基于数据帧传递,根据 opcode 来区分操作类型
数据分片
WebSocket 接收方每收到一个数据帧都会根据 FIN 来判断是否已经收到消息的最后一个数据帧。此时 opcode 在数据交换的场景下表示数据类型,如 0x01 位文本,0x02 为二进制。0x00 表示延续帧 continuation frame,表示完整消息对应的数据帧还没接收完。
第一条消息表示发送的是文本类型,第二、三条消息表示完整消息未被接收完,第四条消息表示文本类型。
1 | Client: FIN=1, opcode=0x1, msg="hello" |
心跳
引入TCP/IP的心跳、KeepAlive问题
对应 WebSocket 操作中的 ping 和 pong,opcode 分别为 0x9、0xA。
一文读懂即时通讯应用中的网络心跳包机制:作用、原理、实现思路等
在绝大部分场景中,由客户端来发送心跳是最佳实践。考虑到 Session 残留的情况:TCP 的保活机制非常不灵敏,完全不适用于正常业务场景,所以使用底层代码库实现的 max_idle_time 来限制。
心跳保活与 idle_time
通过心跳保活与 WebSocket 底层实现库设置 idle_time 来使残余 Session 关闭。在笔者的设计中,在 WS 握手成功后的连接回调函数中,会为该连接对应的 Session 设置一个 max_idle_time,后续过程中,由客户端来发送心跳保活。
笔者业务中使用的是原生的 websocket 包,可以看到核心代码如下:
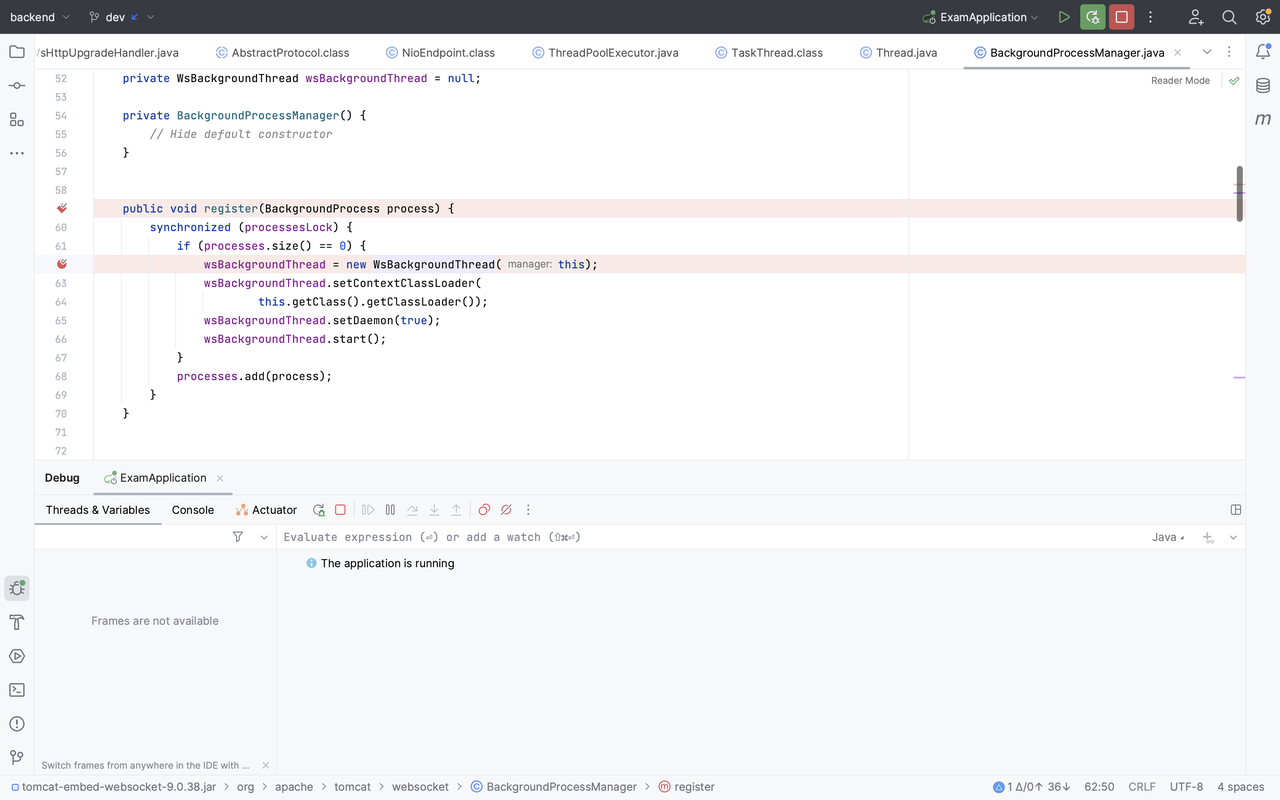
在建立连接后,如果当前 endpoint 对应的 SessionMap 没有 Session(意味着当前连接是第一个连接),会创建一个后台线程,然后注册当前 Session 到内存中的 sessions 中,这是一个 map,key 和 value 存放的都是 WsSession 实例。

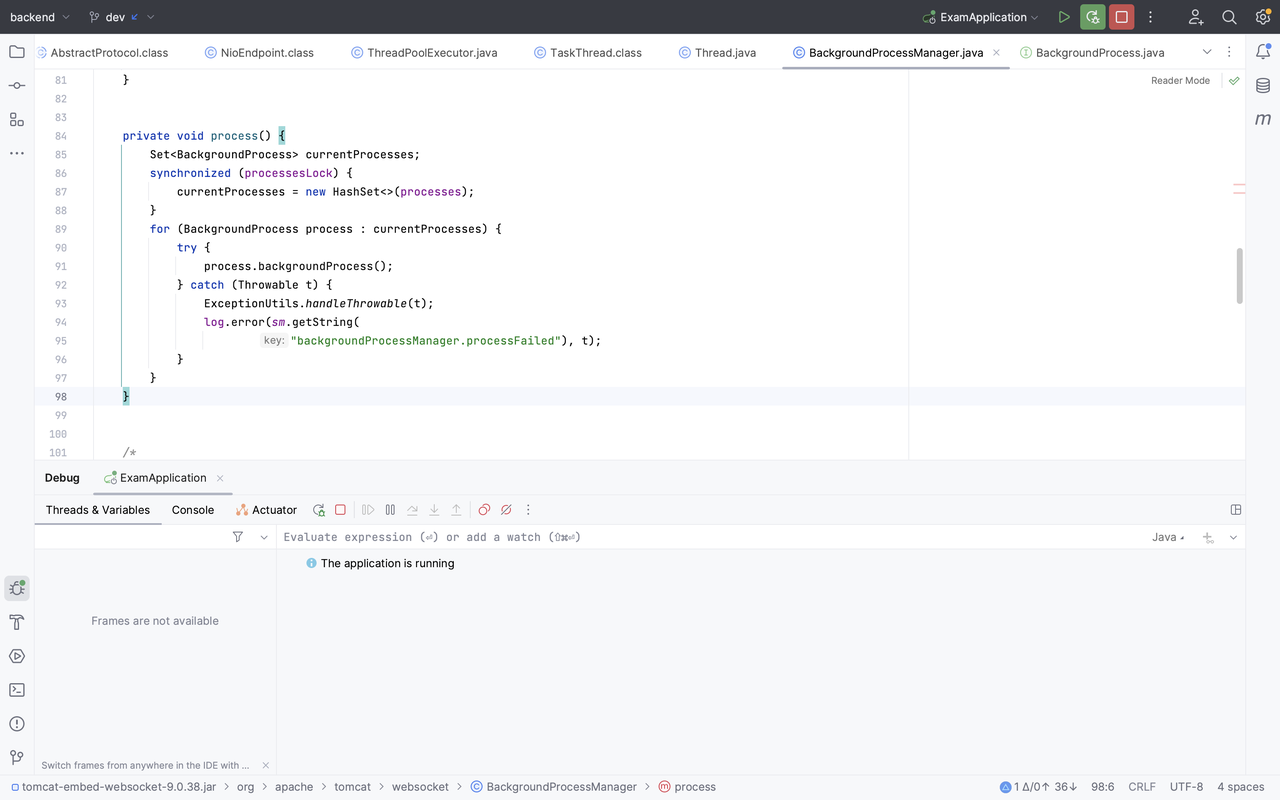
其实上图走的是BackgroundProcessManager.getInstance().register(this);

在调用BackgroundProcessManager.getInstance().register(this)时,会开一个 WsBackgroundThread 线程,它的主要任务是每秒跑一次manager.process(),它会获取所有 process,并一一执行process.backgroundProcess()
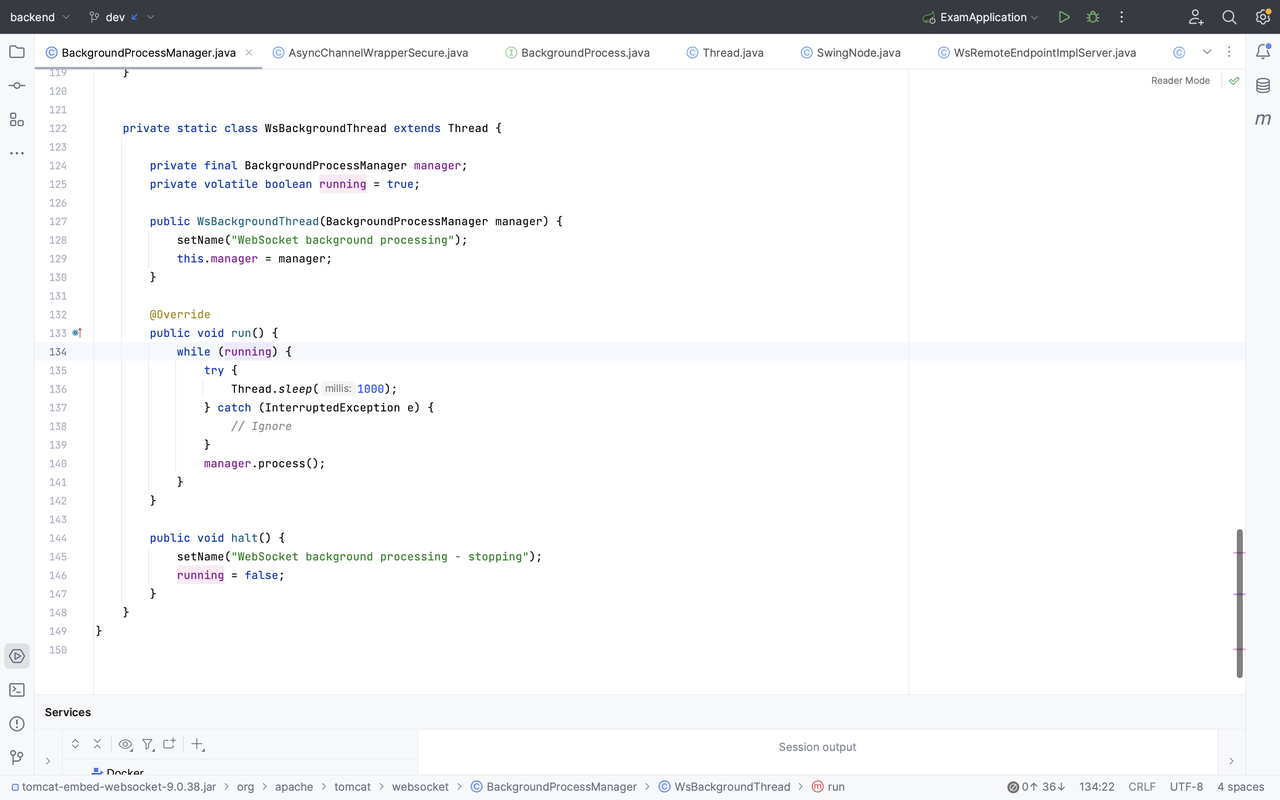
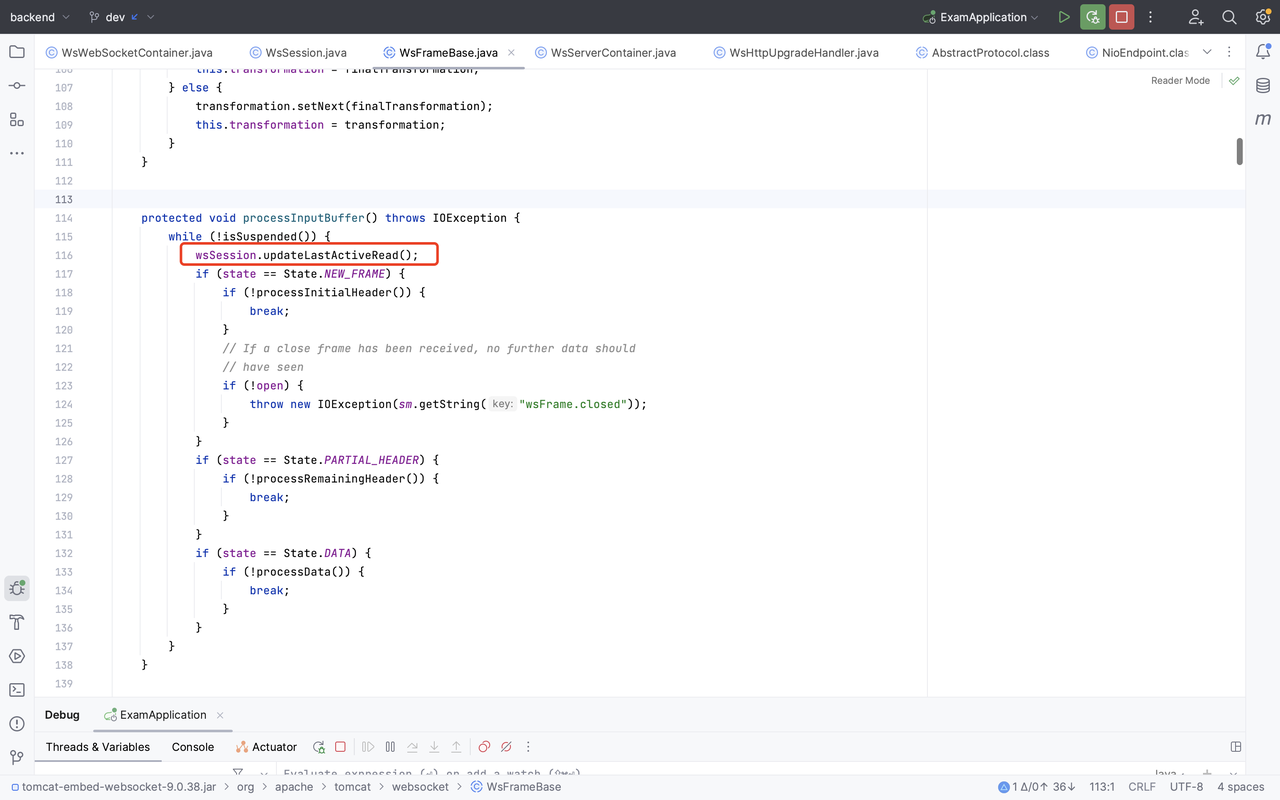
对应到 WsWebSocketContainer 的实现,即获取每个 Session 的实例,调用 checkExpiration,下面代码贴在一起:
核心判断语句是:(timeout > 0 && (currentTime - lastActiveRead) > timeout && (currentTime - lastActiveWrite) > timeout),它检查上次读/写活跃时间是否已经超过了设定的最长空闲时间 maxIdleTimeout,如果超过,则调用 doClose 回调函数,主动关闭 Session。
1 |
|
至于更新 lastActiveRead 与 lastActiveWrite,自然会在读写时做更新。
1 | protected void updateLastActiveRead() { |
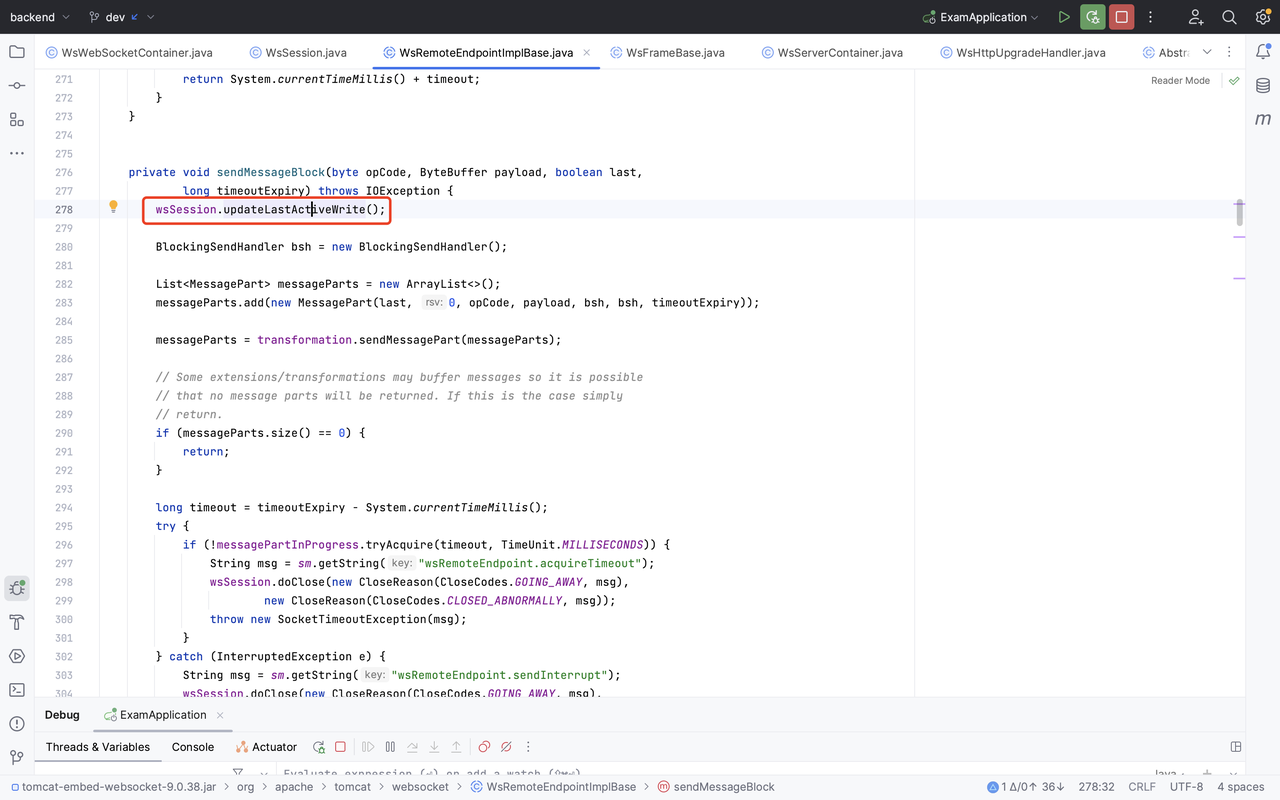
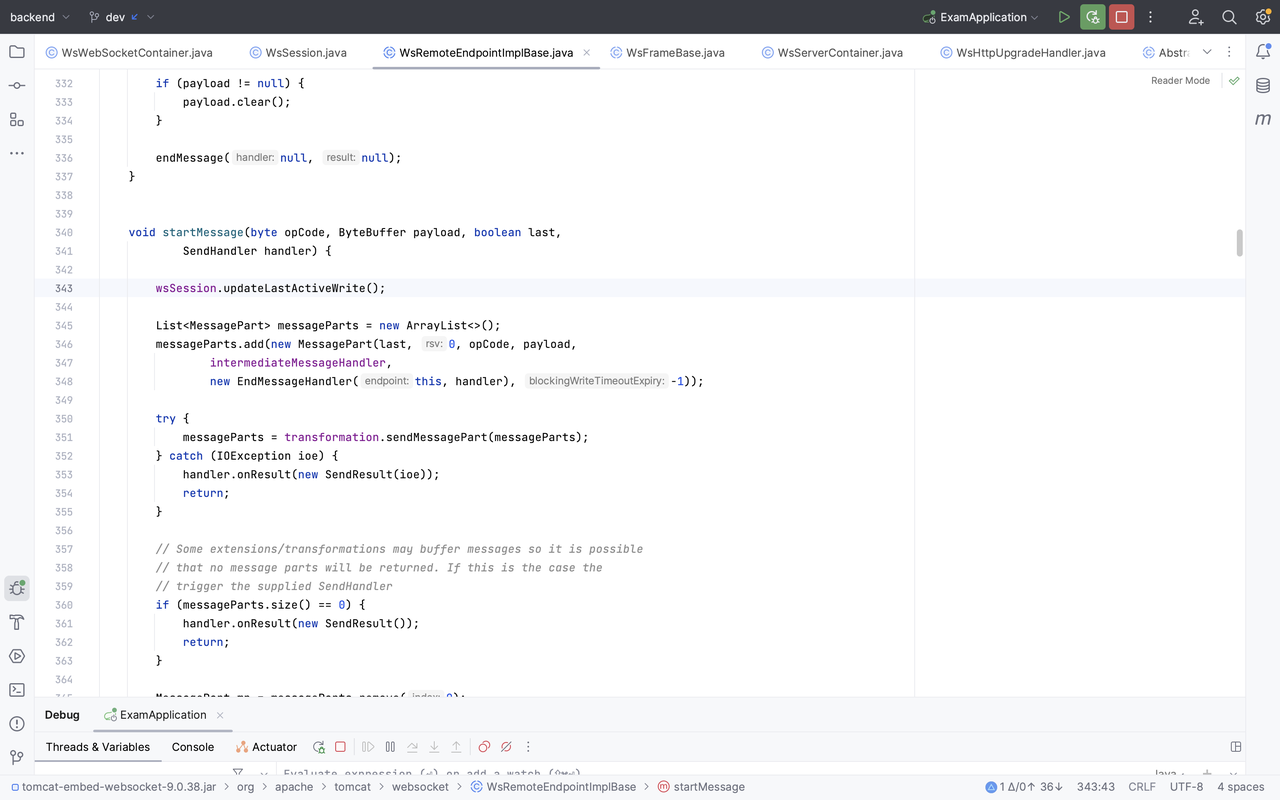
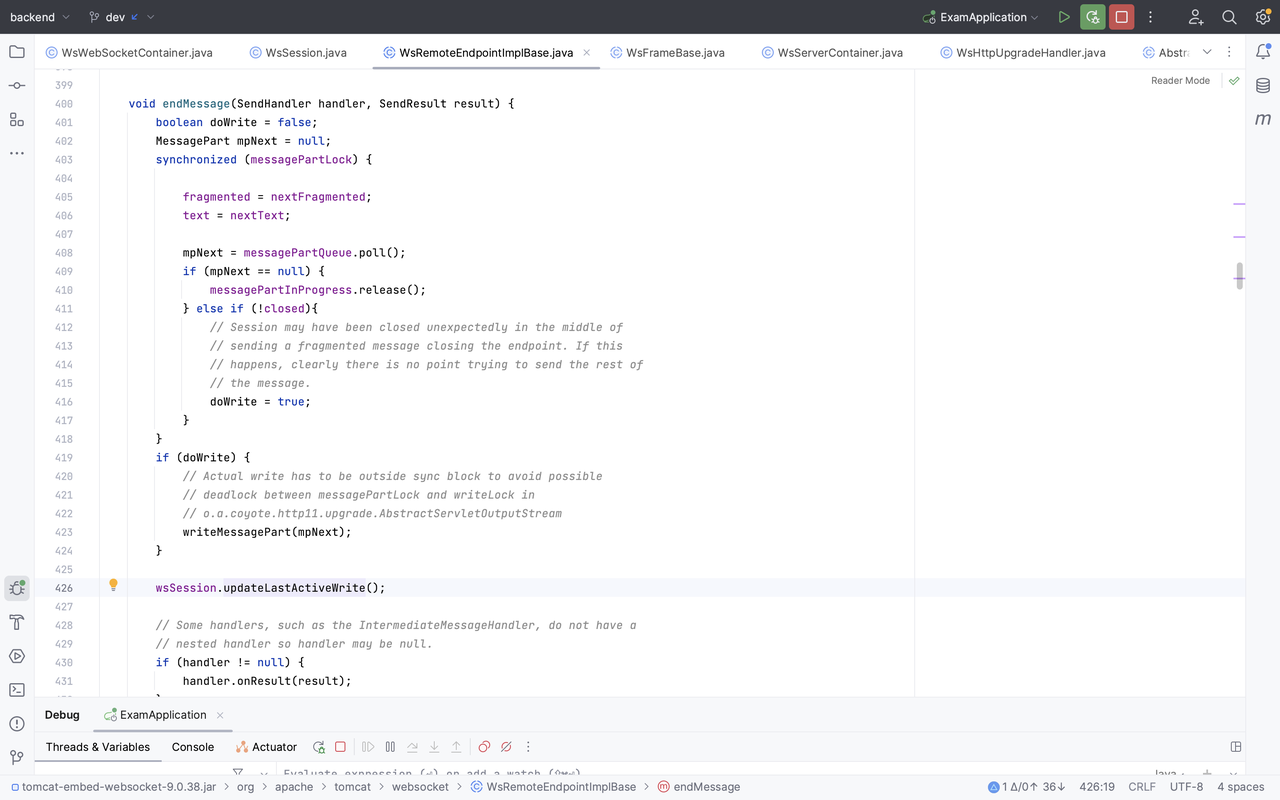
以上就是 WebSocket 代码库 idle_time 实现清除参与 Session 的原理。
一句话来说:就是底层代码库会为 endpoint 创建 background 线程,每秒一次去 checkExpiration,主要检查 lastActiveRead 与 lastActiveWrite 是否距离当前时间已经超过了 maxIdleTimeout。
长连接实时推送网关
解决痛点
-
技术栈不统一,开发和维护困难
-
WebSocket 实现分散在各个工程,与业务系统强耦合,其余业务需要集成时,会有重复开发、浪费成本的情况,效率低下
-
WebSocket 是有状态协议,集群需要解决共享会话功能,如果单节点部署无法水平扩展支撑更高负载,有单点风险
-
缺乏监控和报警。虽然可以通过 LinuxSocket 连接数大致估计,但是不准确,且没有业务指标数据,无法与现有微服务框架整合
技术目标和价值
-
封装 WebSocket 通信细节,与业务系统节藕,双方可以独立迭代,避免重复开发,便于开发和维护
-
提供了 HTTP 接口,便于各个其他开发语言接入,便于系统集成和使用
-
采用分布式架构,实现服务水平扩展、负载均衡和高可用
-
网关集成监控和报警,便于及时排查和解决问题
技术选型
选用:Netty:高性能,易扩展,社区活跃
WebSocket 是有状态的,无法像直接 HTTP 以集群方式实现负载均衡,长连接建立后即与服务端某个节点保持着会话,因此集群下想要得知会话属于哪个节点有点困难。
一般有如下两种解决方案:
-
使用类似微服务的注册中心维护全局的会话映射问题
-
使用事件广播由各节点自行判断是否持有会话

广播实现方案,其实就是选 mq:

在笔者所参与的项目中,由于业务场景中消息无需保证可靠,因此选用:Redis 的 Pub/Sub,少一个依赖的 mq,维护方便,实现简单。如果需要保证消息可靠,还是推荐 RocketMQ 或者 Kafka。
实现思路
架构图:
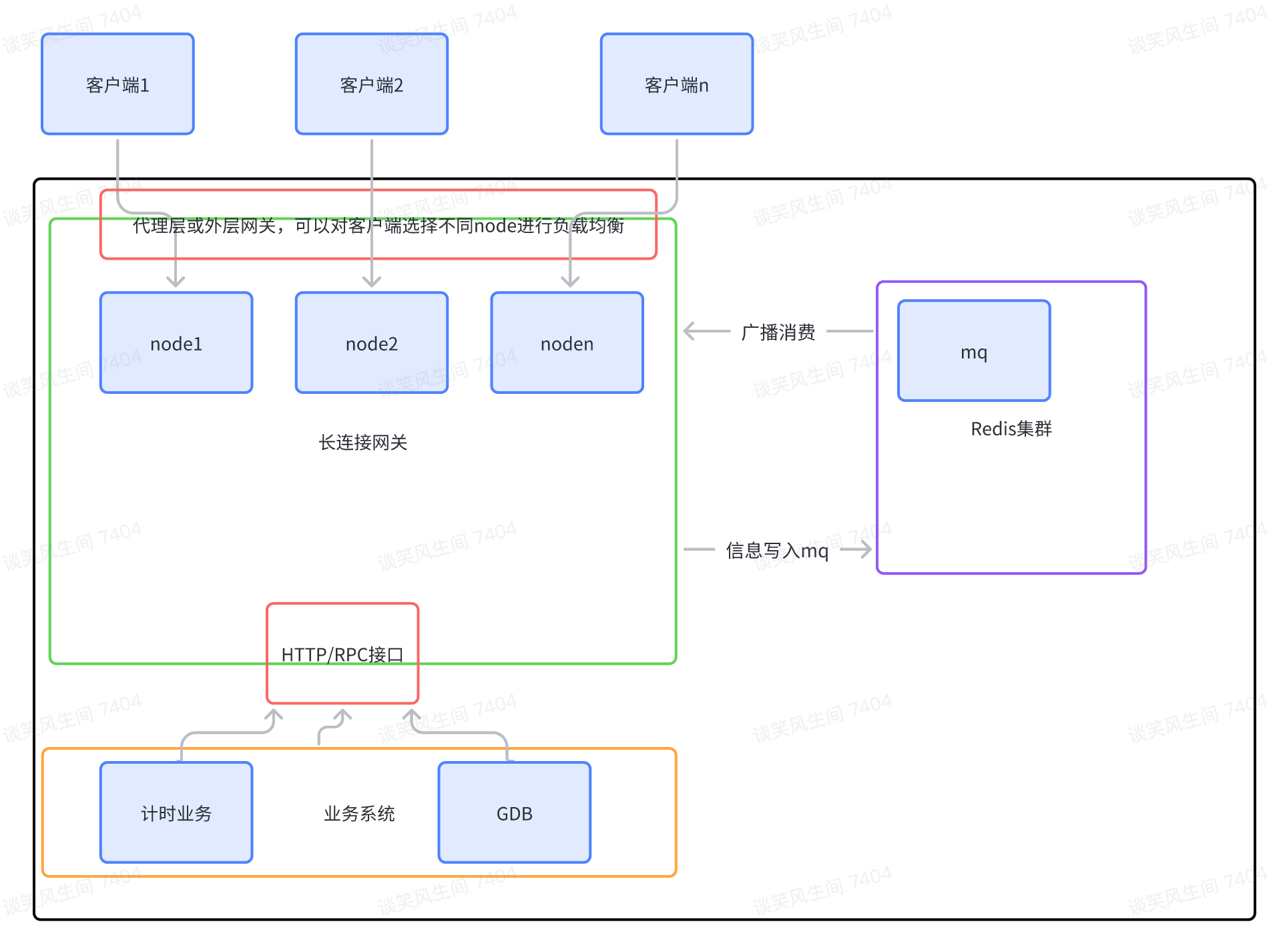
网关整体流程:
-
客户端与网关任意一个 node 握手建立长连接,节点将其加入到内存维护的长连接队列(集合)中。客户端定时向服务端发送心跳,如果超过设定时间仍没有收到心跳,则认为客户端与服务端的长连接已断开,服务端回关闭连接,清理内存中会话。详见心跳
-
当业务系统需要给客户端推送数据时,通过网关提供的 HTTP 接口向网关发送请求
-
将数据信息写到 mq 里
-
网关作为消费者,以广播模式消费消息,所有节点都会接收到消息。
-
节点接收到消息后判断消息目标是否在自己内存中维护的长连接队列里,如果存在则通过长连接推送数据,否则忽略
当面对海量连接时,可以通过网管多节点,增加节点的方式分摊压力,实现水平扩展。如果节点宕机,客户端会尝试和其他节点握手建立长连接,保证服务整体可用。
会话管理:
每个 node 内存中维护一个哈希表,哈希表维护了 UID 和 UserSession 的关系。
UID 即用户 ID,UserSession 表示用户纬度的会话,一个用户困难会同时建立多个长连接,因此 UserSession 内部同样适用了一个哈希表维护一个 Channel 与 ChannelSession 的关系。
为了避免无止尽创建长连接,当内部 ChannelSession 数量超过一定限制后,会将最早建立的 ChannelSession 关闭,减少资源占用。
通过心跳保活与 WebSocket 底层实现库设置 idle_time 来使残余 Session 关闭。详见心跳
监控和报警:
网关接入micrometer,将连接数和用户数作为指标暴露,供prometheus收集,使用Grafana来展示和报警
负载均衡策略
负载均衡策略五花八门,需要选择合适自己的业务场景来设定。简单的做法是直接 ip hash 分到不同 node 上。也可以为 WebSocket node 设一个接口获取负载情况,再做相应的决定。
笔者尝试了一种比较有意思的方案:一文了解一致性哈希,仅供参考。
压测
由于笔者设备能力有限,此处借用原文爱奇艺的测试数据,从下文数据可以看到,该长连接网关的性能非常优秀,足以支撑笔者业务中大部分场景,而且易横向扩展。
压测选择两台配置为 4 核 16G 的虚拟机,分别作为服务器和客户端。压测时选择为网关开放了 20 个端口,同时建立 20 个客户端,每个客户端使用一个服务端端口建立起 5 万连接,可以同时创建百万个连接。连接数与内存使用情况如图 3 所示。
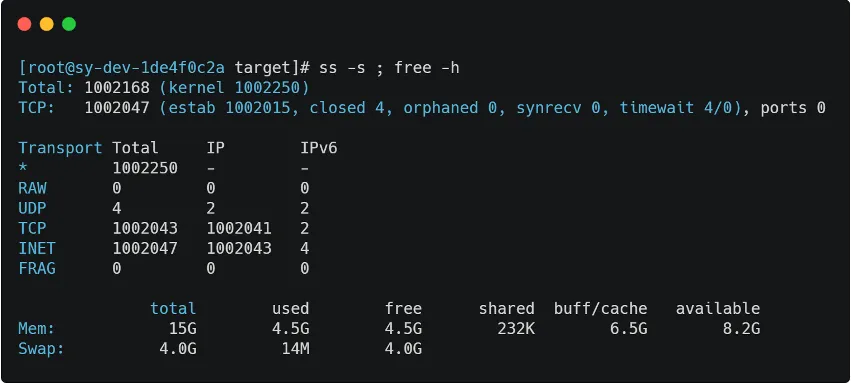
给百万个长连接同时发送一条消息,采用单线程发送,服务器发送完成的平均耗时在 10s 左右。
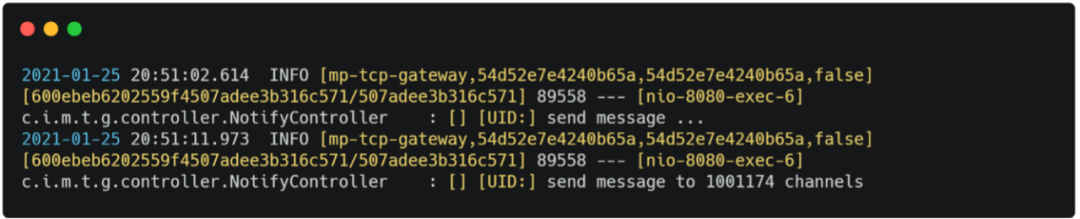
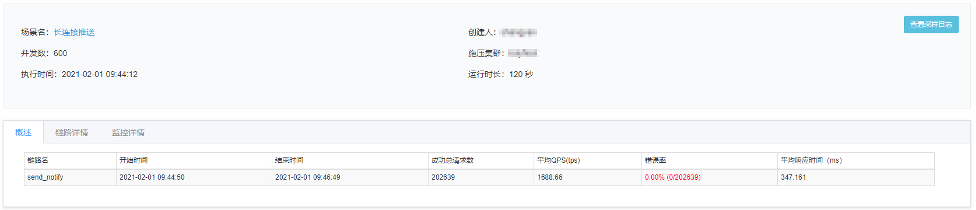
一般同一用户同时建立的长连接都在个位数。以 10 个长连接为例,在并发数 600、持续时间 120s 条件下压测,推送接口的 TPS 大约在 1600+。
参考与推荐阅读
- https://mp.weixin.qq.com/s/x8tjsZRuLlNYHg04aW7KFw
- http://www.adambarth.com/papers/2011/huang-chen-barth-rescorla-jackson.pdf
- https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API/Writing_WebSocket_server
- RFC ft-ietf-hybi-thewebsocketprotocol: The WebSocket Protocol
- https://blog.moontalk.top/post/why-websocket-masked/
- https://datatracker.ietf.org/doc/html/rfc6455#section-10.3
- 构建通用 WebSocket 推送网关的设计与实践
- http://www.52im.net/thread-2697-1-1.html
- https://medium.com/@lancers/websocket-api-sec-websocket-protocol-subprotocol-header-support-277e34164537