一文了解 GoFound
GoFound 去发现,去探索全文检索的世界,一个小巧精悍的全文检索引擎,支持持久化和单机亿级数据毫秒级查找。
基础概念
全文检索
全文检索一般有两种方法。一是从头到尾扫描作为检索对象的文档,以此来搜索要检索的字符串,如 Unix 中的grep命令,但是文档数量越多,文档越大,检索的时间会越长,甚至超出预期上限。另一种是利用索引进行全文搜索,事先为文档建立索引,尽管建立索引可能需要不少时间,但是优点是即使文档的数量增加,检索的速度也不会大幅下降,GoFound 也是采取这种方式。
倒排索引
倒排索引与词典索引类似,用一本书的倒排索引作为示例,key 存储了单词,value 存储了一个组成页数的数组,当你需要查找I search keywords in Google.这句话时,你可以很直观的看到它的单词在哪一页。
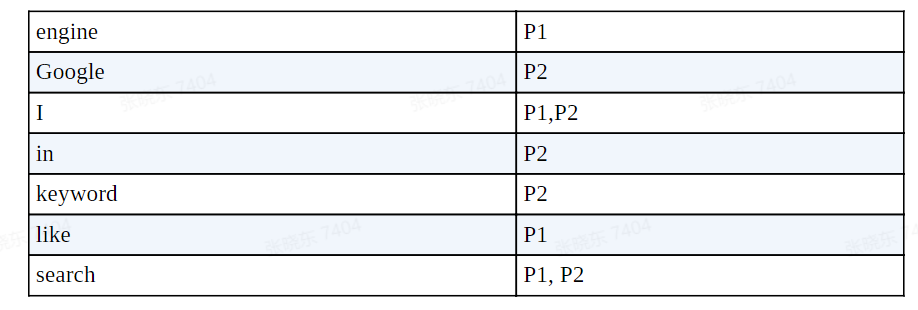
倒排索引中,每个单词都有一个引用指向属于它的一个倒排列表,倒排列表中存储了众多的倒排项,倒排项即文档 ID。取出多个单词的倒排列表后,可以根据情况进行交集处理与评分,获取到更符合预想的搜索结果。
正排索引
正排索引存储了文档 id 和索引词组的映射,便于在修改索引时判断索引 text 变更,以及计算相关度。
文档
文档是作为检索对象的数据,在全文搜索中,通常将构建索引的单位称为文档 (Document),将文档的唯一标识信息称为编号 (文档 ID)。可以说,倒排索引就是将单词和单词所在文档的文档编号对应起来的表格。
分词与词典
由于中文不像英文那样有空格隔开,中文分词手段主要依靠了字典和统计学。
GoFound 使用的中文分词组件是结巴分词,支持精确模式、全模式、搜索引擎模式和 paddle 模式四种分词模式。分词时采取的是搜索引擎模式CutForSearch,在精准模式的基础上试图将长词分为若干个短词,提高召回率。CutForSearch()会返回一个 channel,用于防止分词阻塞以及接收分词后的短语。
GoFound 通过 jieba 的接口载入自定义词典,在调用的 jieba-go sdk 中,jieba 通过将词典的每一个词以及该词的词频、词性封装为Token,将其存入 map,设定词频为其所给词频,然后将该词继续分割为前缀词,将前缀词加载入词典中,设定前缀词词频为 0.0
1 | func (d *Dictionary) addToken(token dictionary.Token) { |
数据结构与定义
索引实体-IndexDoc
1 | // IndexDoc 索引实体 |
文档对象-StorageIndexDoc
1 | // StorageIndexDoc 文档对象 |
响应文档结果-ResponseDoc
1 | type ResponseDoc struct { |
删除文档索引模型-RemoveIndexModel
1 | type RemoveIndexModel struct { |
搜索请求-SearchRequest
1 | // SearchRequest 搜索请求 |
搜索响应-SearchResult
1 | // SearchResult 搜索响应 |
存储结构-LeveldbStorage
1 | type LeveldbStorage struct { |
分页限制-Pagination
1 | type Pagination struct { |
容器-Container
真的难以形容这个命名,实际上也只是将引擎封装了一波
1 | type Container struct { |
引擎-Engine
引擎其实就是一个 GoFound 数据库结构的封装,包含了正排索引、倒排索引以及文档数据的存储结构,还有分词器和添加索引工作 channel,分片数配置等。
1 | type Engine struct { |
执行流程
初始化
- 解析配置文件信息
- 包含设置默认值
- 初始化分词器和容器
- 分词器:调用 jieba 分词的 api
LoadDictionary加载路径下的词典data/dictionary.txt - 容器:包括设置加载配置中的参数,如数据目录,分片数,超时时间和分片缓冲数,以及分词器。并创建数据目录,初始化引擎,加载数据库,如果有多个数据库(数据目录下有多个目录),则会创建多个引擎,数量相等于数据库数量。当该数据库不存在时,会创建数据库。
- 初始化引擎:主要用于管理索引、文档存储相关内容,会初始化一些参数如分片数
Shard、分片缓冲数BufferNum。还会初始化索引引擎。 - 初始化索引引擎:为每个分片都创建一个个 channel 用作添加索引缓冲,缓冲 channel 的缓冲区大小为 BufferNum,并设定一个工作 g 专门用于添加文档索引。为每个分片新建索引文档、正排索引和倒排索引的存储结构。设定一个 g 用于自动 GC(10s 一次)。
- 分词器:调用 jieba 分词的 api
- 初始化业务逻辑
- 初始化基础管理,数据库管理,索引管理和分词管理,注册相应的回调函数。可以由统一的全局变量 srv 来调度
- 注册路由
- 选择是否开启 gzip 压缩,设置 basic 认证
- 分组注册路由以及中间件
- 启动服务
- 开启一个 goroutine 启动服务
- 优雅关机
- 接收到 os 的 signal 时会等待五秒,取消所有的请求再关闭
添加、更新索引
在这里要提到文档的 Id,文档 Id 是用户自己设置的,而不是 GoFound 给予的。接口的处理方法是异步添加索引,在接收到索引实体 (IndexDoc) 后,自增文档数量并把文档的索引实体传入文档中,返回 nil。
1 | func (e *Engine) IndexDocument(doc *model.IndexDoc) error { |
在初始化时已经为每个分片创建了一个 g 用来添加索引工作,处理对应缓冲 channel 的文档。工作 g 执行方法是在 for 中等待 worker channel 传来的 doc,然后调用添加文档方法AddDocument(),此处才真正开始处理添加文档和索引。
首先是调用分词器对索引的原始文本进行分词,然后调用optimizeIndex()检测是否需要更新倒排索引,获取新插入的以及需要更新倒排索引的词组。调用getDifference(id)获取索引词组新旧的差别,这里传入了文档 Id,通过正排索引查找出旧索引的词组,比较俩词组的区别,返回需要新增的,需要移除的词组。如果新词组与旧词组不一致,先移除需要移除词组的倒排索引,将需要插入的词组返回,由AddDocument()进行处理。对需要新增的词组调用addInvertedIndex()添加倒排索引,最后调用addPositiveIndex()更新覆盖正排索引以及文档存储。至此添加与更新索引结束
删除索引/文档
删除文档的处理较为简单,但因为没有加锁处理可能会导致不寻常的意外发生,这些我们在后文细谈。通过接收到的文档 id,查找相应的正排索引,如果没找到则直接返回。删除获取到的索引词组对应倒排索引的文档 id 映射,删除文档存储,并减少 engine 的 documentCount。
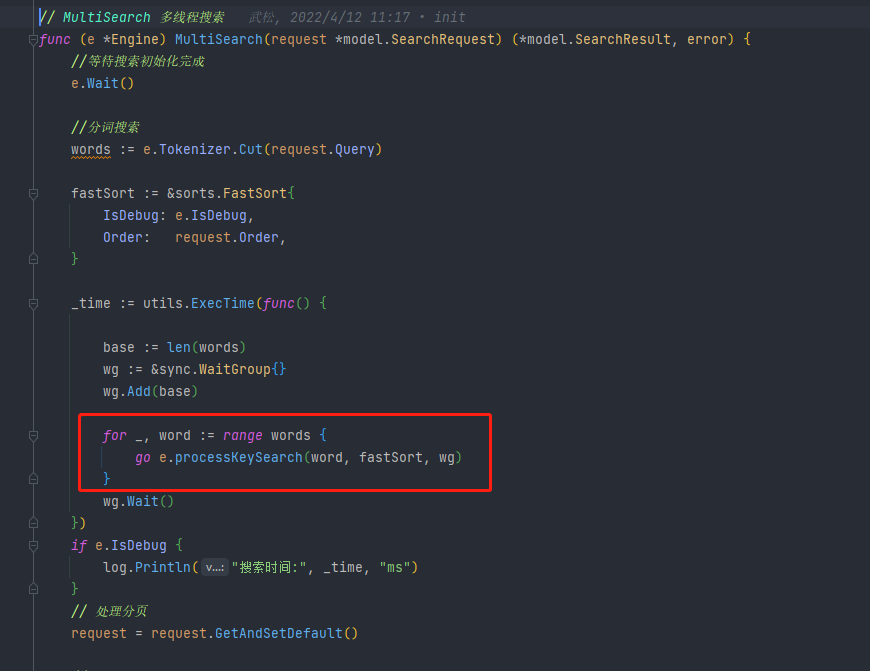
查询
查询调用的是 engine 的方法MultiSearch()多线程查询。先对查询文本进行分词,设定排序模式,对每一个词都开启一个 g 调用processKeySearch()进行搜索。获取到该词所在分片的倒排索引映射的一组文档 id,将文档 id 数组加入 fastSort 的 temps 中,等待进一步处理。处理完每个词后,还需要进行交集得分和去重,在fastSort.Process()中进。上一步已经将所有词组相关的文档 id 存入了 fastSort 的 temps 中,先将 temps 进行排序,遍历 temps,根据 id 的数量来增加 id 对应的分数,将分数统计加入到 fastSort.data 中,它是个 SliceItem 数组,记录了文档 id 以及对应的分数。统计完成后,对 fastSort.data 进行降序排序,然后开始处理分页和进行自定义分数统计。
分页统计也很简单,计算取得数据的区间,直接获取fastSort.data[start:end]即可。
对于每个 SliceItem,启动一个 g 去获取该 SliceItem 的文档 id 对应的文档数据,进行文档存储的 gob 解析,使用request.Highlight高亮原始索引文本里的本次的索引词组。调用第三方 govaluate 包进行表达式解析、执行 (Evaluate),并更改评分,如果此时排序模式是倒序的,则需要将顺序对调,再返回即可。
性能实测
笔者测试虚拟机配置为 6 核 6G Linux 发行版为 Ubuntu22.04
1 | $ uname -a |
添加索引
添加索引速度很慢,同时占用 cpu 高,可以看到 index 处是枚举每个文档进行插入的,而且 channel 也有缓冲数量,限制了添加索引的速度,默认 shard 为 10,buffnum 为 1000 时差不多 200 个索引/10s。在 AddDocument() 中,对索引进行操作都有全局锁锁住,特别是 optimizeIndex(),在计算新旧索引词组的时候也一并锁住了,影响了 g 的并发性能。个人认为此处只锁住 id 就行了,对于更新正排索引而言,还需要锁住词组即可,这样可以保证多个 g 并行添加索引,又保证了数据的安全性。
1 | // BatchAddIndex 批次添加索引 |
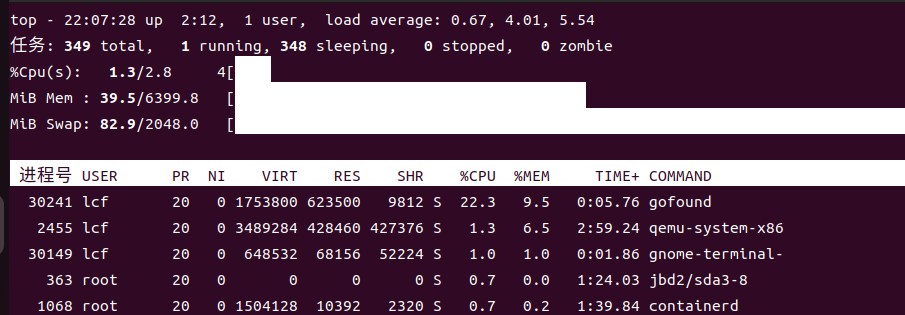
添加索引时会占用大量 cpu(3 核)与部分内存(2G)
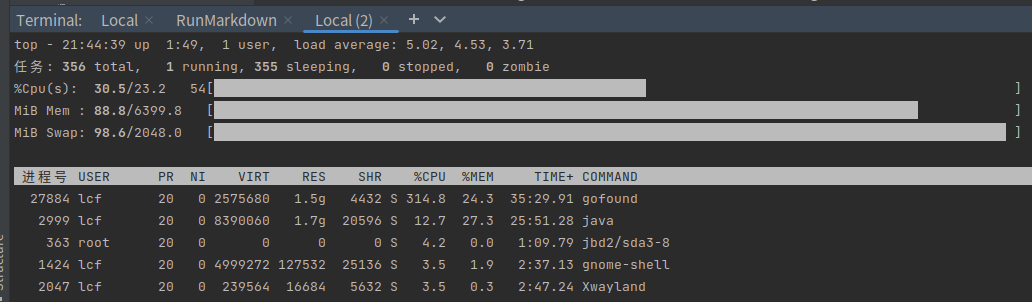
正常启动并添加 5w 数据后内存恒定占 2G
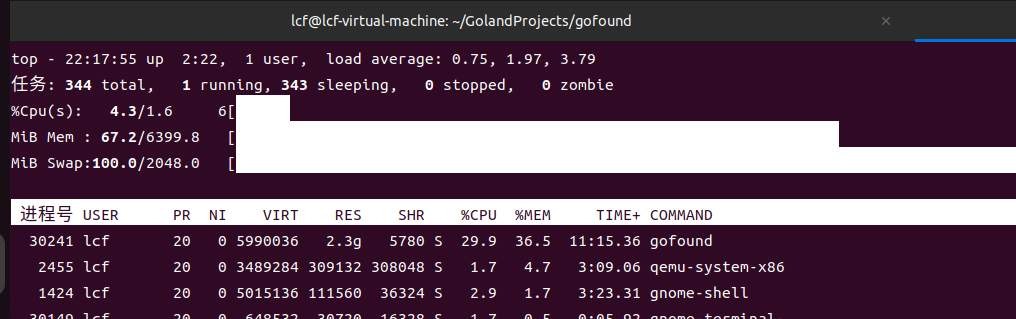
查询性能
虽然代码比较简单,但是查询性能还是挺给力的,笔者 mock 了 5w 数据写入,搜索长度 45 的句子,在 3w 数据中还是达到毫秒级的
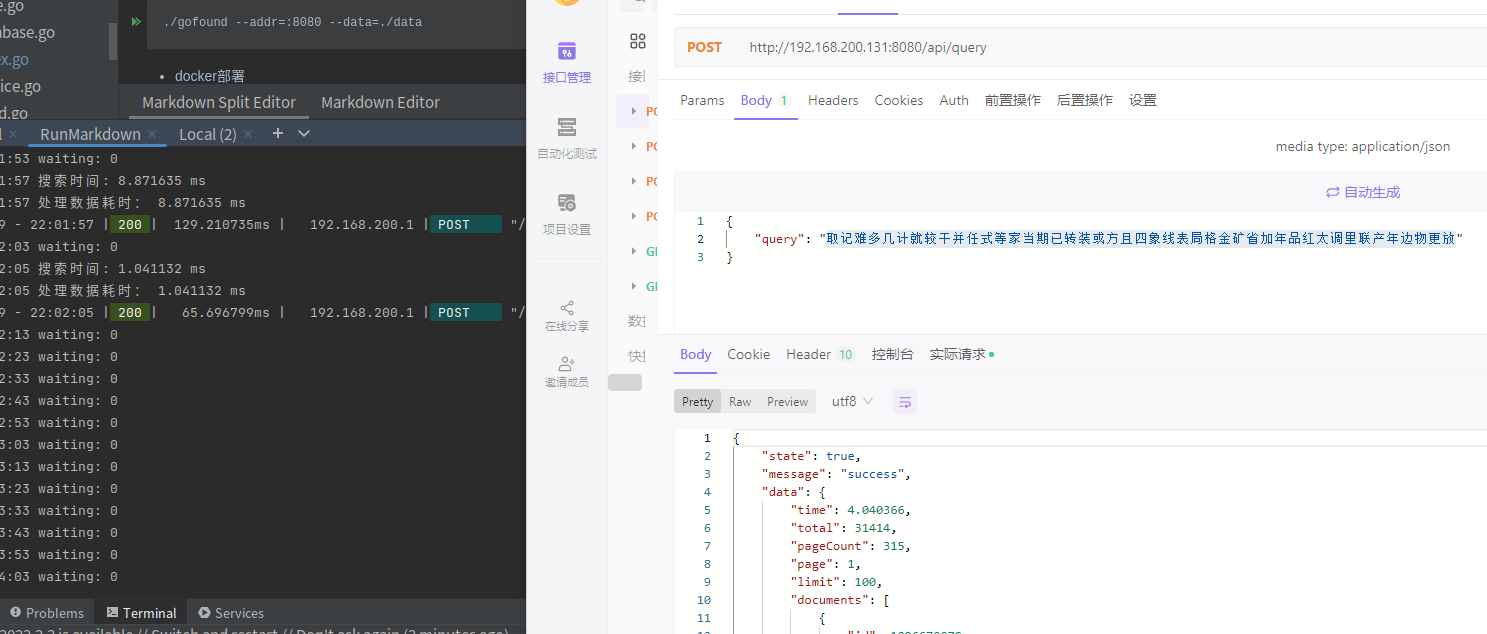
查询过程中会占用少量 cpu
问题与优化
搜索结果不稳定
笔者同一查询参数去查询时 total 的数量不稳定
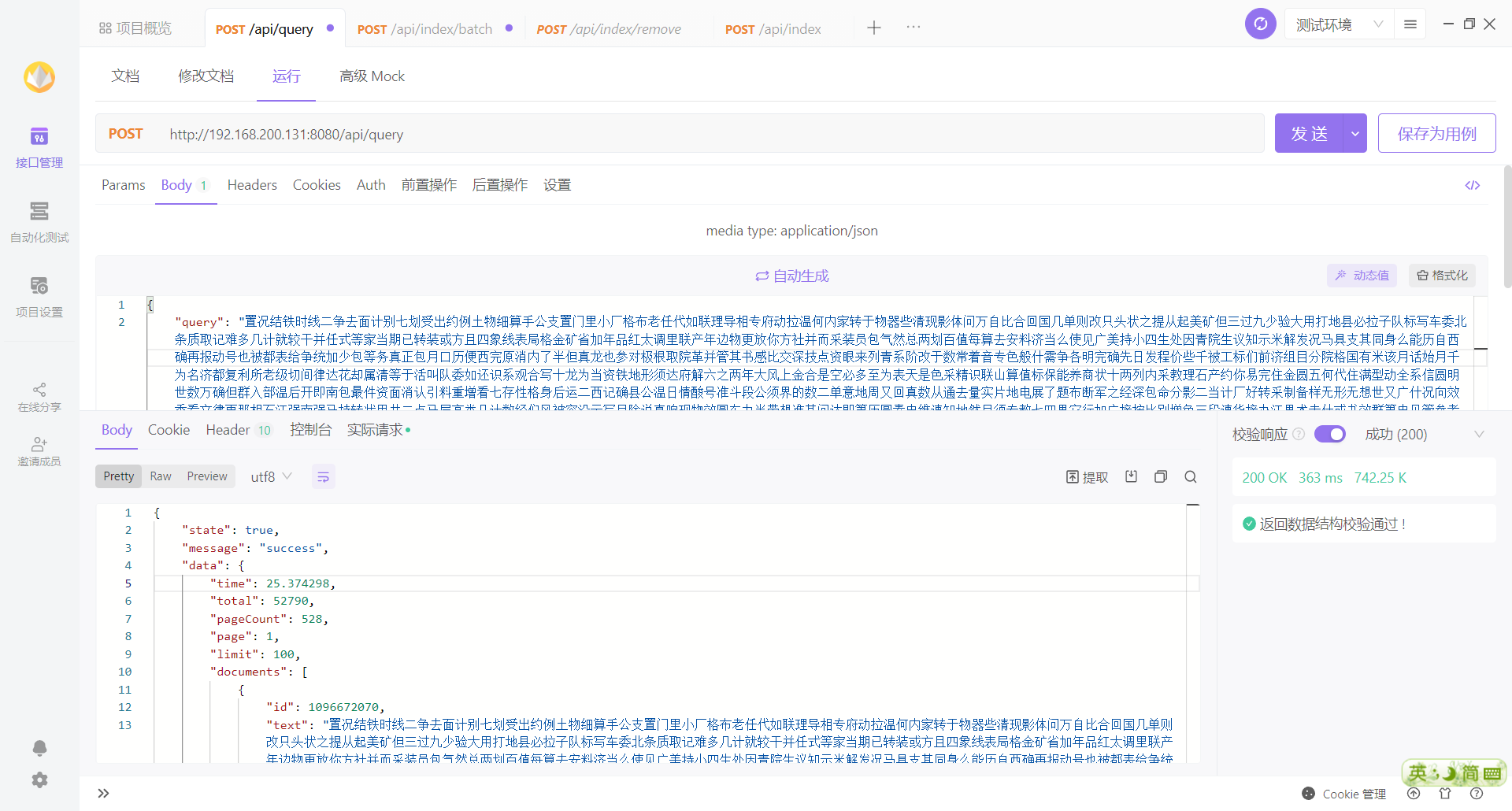
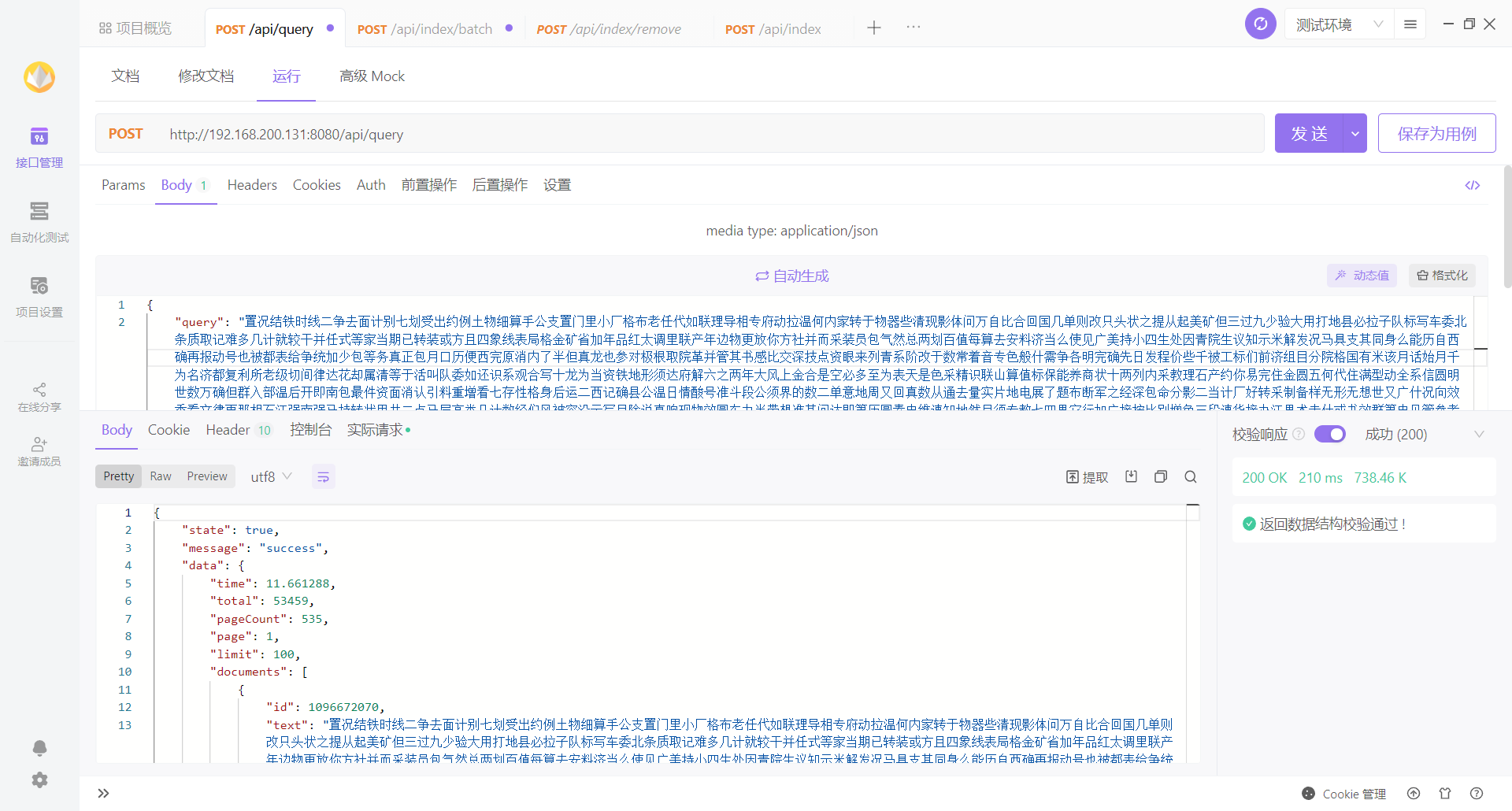
修改分片可能会导致数据正常无法访问到
没有做相应的分片数据转移和负载均衡功能
查询过程中没有有意地控制 g 的数量
每一个词一个 g,数据量较大时会 oom